What makes a successful TV show?
This analysis and model attemts to determine the factors that influence high or low IMDb ratings for TV shows. All generes are examined, and while most originate in the United States, there are a few from the UK and elsewhere included.
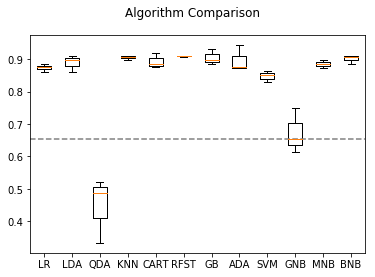
Two separate models are developed. In both, the top and bottom rated shows are classified as winners and losers, respectively, and an array of 12 classisfiers are applied using cross validation to identify the best performing model. 25% of the data was reserved as a test set, and cross-validation scores and test set scores are both shown in the tables below. Baseline score is 0.52.
The first utilizes natural language processing (NLP) on the IMDb summary descriptions of each show. Term Frequency - Inverse Document Frequency and Count Vectorization were used on n-grams of size 2-4 were used. With both vectorization techniqes, Random Forrest and Naive Bayesian classifiers were most successful, with the highest score of 0.642 was achieved using TF-IDF vectorization and a Multinomial Naive Bayes classifier. The n-grams with highest cumulative score are identified as the most significant factors in the model, giving a clue as to the words in a summary description that foretell a show’s likelihood of being a winner or loser.
A second model, using factors such as genre, lenght, schedule times, network and format was also built, and the same set of 12 classifiers was applied. The ADA Boost classifier achieved the top score of 0.92 using these factors.
Data collection and cleanup was tedious, and involved multiple runs of webscraping IMDb pages on show ratings, then using the TVmaze API to return show detals. Unless interested in these details, the reader is encouraged to skip to the section titled “Modeling Section” a bit more than halfway through this notebook.
Results Summary:
From the NLP models, it seems shows featuring adult characters in crime and drama series set in times before or after the present in New York will fare better than reality or animated series featuring children or teens and highlighting pop culture.
The model on the factors other than the summary showed similar tendencies. Realty formats were the strongest negative factor in predicting success, while the scripted format was the strongest positive predictor. Game and Talk shows were negative, while crime, science fiction, comedy, drama and documentaries were positive predictors. Shows aired by HBO and BBC predicted success, while the lower rated shows were found more predominantly on MTV, E!, Comedy Central and Lifetime.
Though interesting associations have been found, it must be said that nothing in the techniques used here can be interpreted as causality. For example, it cannot be said that reality shows featuring teenagers will always flop. This report is based on initial efforts to determine factors that may influence a show’s success, and have shown a path for future more detailed modeling. Suggested future paths include textual analysis of critics’ reviews, analysis based on cast or producers, analysis of differences in rating based on audience demographics, and a more detailed look at the connection between genre and the type/style of show.
# Import libraries needed for scraping and saving results.
# Additional libraries needed for modeling, analysis and display will be imported when needed.
import requests
import pandas as pd
from bs4 import BeautifulSoup
import pickle
Data Acquisition: List of top rated TV Shows
# Retrieve current top 250 TV shows webpage
url = "http://www.imdb.com/chart/toptv/"
r = requests.get(url)
html = r.text
html[0:200]
u'\n\n\n\n<!DOCTYPE html>\n<html\nxmlns:og="http://ogp.me/ns#"\nxmlns:fb="http://www.facebook.com/2008/fbml">\n <head>\n <meta charset="utf-8">\n <meta http-equiv="X-UA-Compatible" content="IE=ed'
# Use Beautiful soup to extract the imdb numbers from the webpage
soup = BeautifulSoup(html, "lxml")
# Scrape the IMDb numbers for the 250 top rated shows
show_list = []
for tbody in soup.findAll('tbody', class_='lister-list'):
for title in tbody.findAll('td', class_='titleColumn'):
show_list.append(str(title.findAll('a')).split("/")[2])
show_list
['tt5491994',
'tt0185906',
'tt0795176',
'tt0944947',
'tt0903747',
'tt0306414',
'tt2861424',
'tt2395695',
'tt0081846',
'tt0071075',
'tt0141842',
'tt1475582',
'tt1533395',
'tt0417299',
'tt0098769',
'tt1806234',
'tt0303461',
'tt0092337',
'tt0052520',
'tt3530232',
'tt2356777',
'tt1355642',
'tt2802850',
'tt0103359',
'tt0296310',
'tt0877057',
'tt4508902',
'tt0475784',
'tt2092588',
'tt0213338',
'tt1856010',
'tt0063929',
'tt0112130',
'tt2571774',
'tt0081834',
'tt0367279',
'tt4742876',
'tt4574334',
'tt2085059',
'tt0108778',
'tt0098904',
'tt3718778',
'tt0081912',
'tt0098936',
'tt1518542',
'tt0074006',
'tt2707408',
'tt0193676',
'tt1865718',
'tt0096548',
'tt0072500',
'tt0384766',
'tt0118421',
'tt0096697',
'tt0090509',
'tt0121955',
'tt0386676',
'tt4299972',
'tt2560140',
'tt0472954',
'tt0412142',
'tt0214341',
'tt5555260',
'tt2442560',
'tt5712554',
'tt0200276',
'tt0353049',
'tt1910272',
'tt0086661',
'tt0248654',
'tt5189670',
'tt0121220',
'tt1486217',
'tt0096639',
'tt0120570',
'tt4786824',
'tt1628033',
'tt0348914',
'tt0403778',
'tt5288312',
'tt0459159',
'tt3032476',
'tt0407362',
'tt4093826',
'tt0773262',
'tt0417349',
'tt3322312',
'tt0264235',
'tt0106179',
'tt0286486',
'tt2297757',
'tt0088484',
'tt2098220',
'tt5425186',
'tt0318871',
'tt0094517',
'tt0436992',
'tt1586680',
'tt0092324',
'tt0994314',
'tt0203082',
'tt1606375',
'tt0380136',
'tt0187664',
'tt1513168',
'tt0118273',
'tt0421357',
'tt1641384',
'tt0314979',
'tt5834204',
'tt0092455',
'tt0115147',
'tt4295140',
'tt0080306',
'tt1266020',
'tt1831164',
'tt3920596',
'tt0804503',
'tt1492966',
'tt0053488',
'tt0086831',
'tt0758745',
'tt0995832',
'tt0434706',
'tt2401256',
'tt0423731',
'tt0111958',
'tt0863046',
'tt1733785',
'tt2049116',
'tt0275137',
'tt1305826',
'tt0472027',
'tt2100976',
'tt1489428',
'tt0112159',
'tt4158110',
'tt1227926',
'tt1870479',
'tt0979432',
'tt0106028',
'tt0387764',
'tt0237123',
'tt0047708',
'tt0088509',
'tt0290978',
'tt1984119',
'tt0098825',
'tt2306299',
'tt0280249',
'tt3647998',
'tt0094525',
'tt0163507',
'tt0118266',
'tt0182629',
'tt0080297',
'tt0061287',
'tt1758429',
'tt3671754',
'tt0487831',
'tt0388629',
'tt2575988',
'tt4189022',
'tt0458254',
'tt2788432',
'tt0096657',
'tt0346314',
'tt1474684',
'tt4288182',
'tt0417373',
'tt1298820',
'tt0262150',
'tt1695360',
'tt1230180',
'tt2243973',
'tt0129690',
'tt1632701',
'tt2433738',
'tt0149460',
'tt1124373',
'tt0075520',
'tt1795096',
'tt1442449',
'tt5249462',
'tt2937900',
'tt1439629',
'tt5071412',
'tt0397150',
'tt0083466',
'tt2701582',
'tt5114356',
'tt4156586',
'tt0319969',
'tt0103584',
'tt0302199',
'tt0070644',
'tt1883092',
'tt2311418',
'tt3428912',
'tt1442437',
'tt0362192',
'tt0278238',
'tt0387199',
'tt2384811',
'tt0098833',
'tt0074028',
'tt2303687',
'tt0807832',
'tt0056751',
'tt0173528',
'tt3358020',
'tt0103466',
'tt1526318',
'tt0185133',
'tt0075572',
'tt0112084',
'tt1837492',
'tt2919910',
'tt1299368',
'tt0094535',
'tt1520211',
'tt0108906',
'tt0988824',
'tt5421602',
'tt5853176',
'tt0934320',
'tt0337898',
'tt0495212',
'tt0460681',
'tt2407574',
'tt0290988',
'tt1598754',
'tt1119644',
'tt1220617',
'tt3398228',
'tt0411008',
'tt0163503',
'tt2249364',
'tt1409055',
'tt4270492',
'tt0060028',
'tt0118480',
'tt0925266',
'tt3012698',
'tt0402711',
'tt0068098',
'tt0442632',
'tt1839578',
'tt0043208',
'tt5673782']
# This code has been executed, and the results pickled and stored locally, so no need to run these requests
# to the API again. The api address with key to look up show with imdb number is
# http://api.tvmaze.com/lookup/shows?imdb=<show imdb identifier>
DO_NOT_RUN = True # Do not run when notebook is loaded to avoid unnecessary calls to the API
if not DO_NOT_RUN:
shows = pd.DataFrame()
for show_id in show_list:
try:
print show_id
# Get the tv show info from the api
url = "http://api.tvmaze.com/lookup/shows?imdb=" + show_id
r = requests.get(url)
# convert the return data to a dictionary
json_data = r.json()
# load a temp datafram with the dictionary, then append to the composite dataframe
temp_df = pd.DataFrame.from_dict(json_data, orient='index', dtype=None)
ttemp_df = temp_df.T # Was not able to load json in column orientation, so must transpose
shows = shows.append(ttemp_df, ignore_index=True)
except:
print show_id, " could not be retrieved from api"
shows.head()
# write the contents of an object to a file for later retrieval
DO_NOT_RUN = True # Be sure to check the file name to write before enabling execution on this block
if not DO_NOT_RUN:
pickle.dump( shows, open( "save_shows_df.p", "wb" ) )
Get list of bottom rated TV Series
# This code block was changed multiple times to pull html with different sets of low rated shows
# ultimately about 1200 imdb ids were scraped, and about 1/3 of those could be pulled from the TV Maze API.
url ="http://www.imdb.com/search/title?count=600&languages=en&title_type=tv_series&user_rating=3.4,5.0&sort=user_rating,asc"
r = requests.get(url)
html = r.text
html[0:200]
u'\n\n\n\n<!DOCTYPE html>\n<html\nxmlns:og="http://ogp.me/ns#"\nxmlns:fb="http://www.facebook.com/2008/fbml">\n <head>\n <meta charset="utf-8">\n <meta http-equiv="X-UA-Compatible" content="IE=ed'
# Use Beautiful soup to extract the imdb numbers from the webpage
soup = BeautifulSoup(html, "lxml")
loser_list = []
for div in soup.findAll('div', class_='lister-list'):
for h3 in div.findAll('h3', class_='lister-item-header'):
loser_list.append(str(h3.findAll('a')).split("/")[2])
loser_list
['tt0773264',
'tt1798695',
'tt1307083',
'tt4845734',
'tt0046641',
'tt1519575',
'tt0853078',
'tt0118423',
'tt0284767',
'tt4052124',
'tt0878801',
'tt3703500',
'tt1105170',
'tt4363582',
'tt3155428',
'tt0362350',
'tt0287196',
'tt2766052',
'tt0405545',
'tt0262975',
'tt0367278',
'tt7134262',
'tt1695352',
'tt0421470',
'tt2466890',
'tt0343305',
'tt1002739',
'tt1615697',
'tt0274262',
'tt0465320',
'tt1388381',
'tt0358889',
'tt1085789',
'tt1011591',
'tt0364804',
'tt1489335',
'tt3612584',
'tt0363377',
'tt0111930',
'tt0401913',
'tt0808086',
'tt0309212',
'tt5464192',
'tt0080250',
'tt4533338',
'tt4741696',
'tt1922810',
'tt1793868',
'tt4789316',
'tt0185054',
'tt1079622',
'tt1786048',
'tt0790508',
'tt1716372',
'tt0295098',
'tt3409706',
'tt0222574',
'tt2171325',
'tt0442643',
'tt2142117',
'tt0371433',
'tt0138244',
'tt1002010',
'tt0495557',
'tt1811817',
'tt5529996',
'tt1352053',
'tt0439346',
'tt0940147',
'tt3075138',
'tt1974439',
'tt2693842',
'tt0092325',
'tt6772826',
'tt1563069',
'tt0489598',
'tt0142055',
'tt1566154',
'tt0338592',
'tt0167515',
'tt2330327',
'tt1576464',
'tt2389845',
'tt0186747',
'tt0355096',
'tt1821877',
'tt0112033',
'tt1792654',
'tt0472243',
'tt6453018',
'tt3648886',
'tt1599374',
'tt2946482',
'tt4672020',
'tt1016283',
'tt2649480',
'tt1229945',
'tt2390606',
'tt1876612',
'tt0140732',
'tt1176156',
'tt0158522',
'tt4922726',
'tt0068104',
'tt2798842',
'tt1150627',
'tt1545453',
'tt3685566',
'tt0287223',
'tt4185510',
'tt0329912',
'tt0289808',
'tt0358849',
'tt2320439',
'tt0906840',
'tt0800281',
'tt1103082',
'tt2416362',
'tt3493906',
'tt0381827',
'tt0817553',
'tt0252172',
'tt0799872',
'tt0816224',
'tt1077162',
'tt1918005',
'tt1240983',
'tt1415000',
'tt5039916',
'tt0451467',
'tt0296438',
'tt1159990',
'tt0144701',
'tt4718304',
'tt1095213',
'tt1453090',
'tt0168372',
'tt0425725',
'tt3300126',
'tt1415098',
'tt5459976',
'tt4041694',
'tt2322264',
'tt1441005',
'tt1117549',
'tt0365991',
'tt0364807',
'tt1591375',
'tt3562462',
'tt6118186',
'tt3587176',
'tt1372127',
'tt0445865',
'tt2088493',
'tt4658248',
'tt0103444',
'tt4956964',
'tt1326185',
'tt0406422',
'tt1973659',
'tt1578933',
'tt0446621',
'tt1850624',
'tt0159177',
'tt0490539',
'tt0306398',
'tt0288922',
'tt0465336',
'tt0176397',
'tt1641939',
'tt0498879',
'tt0306296',
'tt1394277',
'tt0398416',
'tt2849552',
'tt1433566',
'tt0806893',
'tt3252890',
'tt3774098',
'tt0791275',
'tt5690224',
'tt0361181',
'tt0486953',
'tt1514319',
'tt3697290',
'tt1342752',
'tt0478936',
'tt0094448',
'tt0795101',
'tt1340759',
'tt0840061',
'tt1151434',
'tt0281429',
'tt0845745',
'tt2993514',
'tt0783634',
'tt1650352',
'tt1249256',
'tt2135766',
'tt3231114',
'tt1702421',
'tt2940494',
'tt6664486',
'tt0081857',
'tt1319598',
'tt0247094',
'tt6392176',
'tt0320969',
'tt2720144',
'tt0360266',
'tt2287380',
'tt1715368',
'tt0282291',
'tt2248736',
'tt2010634',
'tt1489432',
'tt4855578',
'tt1721484',
'tt0380850',
'tt3084090',
'tt2392683',
'tt1381004',
'tt1628058',
'tt2935638',
'tt1837169',
'tt2404111',
'tt2364381',
'tt0888095',
'tt2352123',
'tt1013862',
'tt4295320',
'tt1249227',
'tt1879603',
'tt0167566',
'tt0924528',
'tt0361144',
'tt0133300',
'tt5888698',
'tt1468817',
'tt4006060',
'tt0106096',
'tt0287243',
'tt1287376',
'tt0060032',
'tt1535270',
'tt4831262',
'tt0416397',
'tt1546138',
'tt2203971',
'tt0214353',
'tt0368518',
'tt0382506',
'tt5317980',
'tt2313839',
'tt1202295',
'tt4146118',
'tt1226448',
'tt0403748',
'tt0415448',
'tt4665932',
'tt3016956',
'tt1412249',
'tt1829773',
'tt0872053',
'tt0481443',
'tt0493098',
'tt0039120',
'tt1411598',
'tt0106123',
'tt1740718',
'tt0362153',
'tt1637756',
'tt0120974',
'tt2328067',
'tt0057741',
'tt1261356',
'tt2559390',
'tt0083433',
'tt0380934',
'tt4388486',
'tt0108821',
'tt0115338',
'tt0167735',
'tt0460630',
'tt2330453',
'tt0398429',
'tt0294140',
'tt0804423',
'tt2191952',
'tt1118131',
'tt4016700',
'tt5786580',
'tt0950199',
'tt1760165',
'tt4896654',
'tt0414719',
'tt1675974',
'tt0465343',
'tt1477137',
'tt0115171',
'tt3565412',
'tt0382458',
'tt0945153',
'tt0199278',
'tt1353293',
'tt1426343',
'tt2180165',
'tt5117094',
'tt1191039',
'tt0497857',
'tt0780409',
'tt2670950',
'tt1385183',
'tt3396736',
'tt2563482',
'tt4094138',
'tt0295065',
'tt1696268',
'tt0891053',
'tt0914267',
'tt1786018',
'tt1988479',
'tt1707814',
'tt1595853',
'tt2310444',
'tt5434894',
'tt0267216',
'tt0855313',
'tt1832828',
'tt0426685',
'tt2309561',
'tt2486556',
'tt0284786',
'tt3136814',
'tt1989818',
'tt1179310',
'tt0424748',
'tt1126298',
'tt0944946',
'tt1882639',
'tt0439904',
'tt0875887',
'tt1624991',
'tt2747670',
'tt2324247',
'tt0403810',
'tt1724452',
'tt2366252',
'tt3752894',
'tt0198211',
'tt1491318',
'tt1666205',
'tt2460474',
'tt0303435',
'tt0453329',
'tt0220938',
'tt0299264',
'tt0783341',
'tt0850175',
'tt1191056',
'tt0235917',
'tt0111892',
'tt0166442',
'tt2643770',
'tt5633924',
'tt0075485',
'tt0423657',
'tt5327970',
'tt3326032',
'tt5785658',
'tt2190731',
'tt0101041',
'tt3317020',
'tt4732076',
'tt2305717',
'tt3828162',
'tt0890935',
'tt0449460',
'tt0126175',
'tt3601886',
'tt5062878',
'tt1579911',
'tt0407354',
'tt6723012',
'tt5819414',
'tt4180738',
'tt0300802',
'tt2649738',
'tt3181412',
'tt0382400',
'tt3189040',
'tt0324919',
'tt2168240',
'tt2560966',
'tt0168373',
'tt0403824',
'tt0375440',
'tt3746054',
'tt2488150',
'tt4081326',
'tt5011838',
'tt2644204',
'tt1210781',
'tt0246359',
'tt0048898',
'tt3398108',
'tt5701572',
'tt0426827',
'tt0425714',
'tt1252620',
'tt0800289',
'tt0111991',
'tt0479847',
'tt2429392',
'tt2901828',
'tt4147072',
'tt1442411',
'tt2093677',
'tt0498421',
'tt3006666',
'tt3017190',
'tt0193680',
'tt5952954',
'tt0381759',
'tt2539740',
'tt0369176',
'tt3016990',
'tt0328787',
'tt2197994',
'tt0478753',
'tt4530152',
'tt0372643',
'tt5693024',
'tt0855669',
'tt1263594',
'tt5935350',
'tt1589855',
'tt0367444',
'tt3384116',
'tt3790338',
'tt2007260',
'tt0343300',
'tt0813904',
'tt0883849',
'tt0433296',
'tt1342705',
'tt0444988',
'tt1333495',
'tt0969661',
'tt0272967',
'tt0283184',
'tt0444577',
'tt3064496',
'tt0436996',
'tt1796788',
'tt1879997',
'tt4800624',
'tt0497079',
'tt1755893',
'tt0329824',
'tt2245937',
'tt2147632',
'tt3218114',
'tt1583417',
'tt0367403',
'tt1963853',
'tt4854900',
'tt6415490',
'tt1520150',
'tt0236907',
'tt6672370',
'tt1055136',
'tt5865052',
'tt1231448',
'tt6315022',
'tt4351710',
'tt4346344',
'tt6043450',
'tt0096605',
'tt1181712',
'tt0182623',
'tt0307719',
'tt1056344',
'tt0328795',
'tt0098916',
'tt1584617',
'tt2354136',
'tt4287478',
'tt0426347',
'tt1874006',
'tt2006560',
'tt1694893',
'tt2338766',
'tt0843808',
'tt0115155',
'tt4354068',
'tt1134663',
'tt0495787',
'tt0088539',
'tt5426274',
'tt1797127',
'tt5763656',
'tt0360301',
'tt4245504',
'tt0318214',
'tt0080254',
'tt1430135',
'tt0892562',
'tt2603010',
'tt1038918',
'tt0390746',
'tt3773682',
'tt0969372',
'tt1470839',
'tt1477822',
'tt1056446',
'tt0340474',
'tt5104198',
'tt2815184',
'tt0468998',
'tt0772146',
'tt3920816',
'tt3654000',
'tt1753229',
'tt0865687',
'tt0459631',
'tt1314665',
'tt4660152',
'tt0086685',
'tt0150323',
'tt0338576',
'tt2118185',
'tt0198086',
'tt0412184',
'tt4420148',
'tt0497853',
'tt1240534',
'tt2479832',
'tt0174195',
'tt1999642',
'tt1155579',
'tt1640376',
'tt1227586',
'tt3784176',
'tt1958848',
'tt2778982',
'tt1273636',
'tt0357357',
'tt1287301',
'tt0852784',
'tt0482432',
'tt1651941',
'tt0043235',
'tt2110603',
'tt1178184',
'tt0846757',
'tt0170959',
'tt0413617',
'tt1726890',
'tt0220874',
'tt0859872',
'tt4219276',
'tt0327268',
'tt0843319',
'tt3131346',
'tt0795072',
'tt5650560',
'tt0827847',
'tt1525767',
'tt1043913',
'tt0266179',
'tt0413558',
'tt0307714',
'tt4693416',
'tt0409619',
'tt5684430',
'tt0134269',
'tt5486088',
'tt1252370',
'tt6370626',
'tt3824018',
'tt2555880',
'tt3310544',
'tt2125758',
'tt1973047',
'tt6748366',
'tt0106113',
'tt0934701',
'tt2059031',
'tt0088598',
'tt1056536',
'tt1618950',
'tt6987940',
'tt5915978',
'tt0106008',
'tt0115206',
'tt0120992',
'tt4575056',
'tt2889104',
'tt0428169']
# first_loser_list = loser_list
# This code has been executed, and the results pickled and stored locally, so no need to run these requests
# to the API again
DO_NOT_RUN = True
if not DO_NOT_RUN:
losers = pd.DataFrame()
for loser_id in loser_list:
try:
print loser_id
# Get the tv show info from the api
url = "http://api.tvmaze.com/lookup/shows?imdb=" + loser_id
r = requests.get(url)
# convert the return data to a dictionary
json_data = r.json()
# load a temp datafram with the dictionary, then append to the composite dataframe
temp_df = pd.DataFrame.from_dict(json_data, orient='index', dtype=None)
ttemp_df = temp_df.T # Was not able to load json in column orientation, so must transpose
losers = losers.append(ttemp_df, ignore_index=True)
except:
print loser_id, " could not be retrieved from api"
losers.head()
tt0465347
tt0465347 could not be retrieved from api
tt4427122
tt4427122 could not be retrieved from api
tt1015682
tt1015682 could not be retrieved from api
tt2505738
tt2505738 could not be retrieved from api
tt2402465
tt2402465 could not be retrieved from api
tt0278236
tt0278236 could not be retrieved from api
tt0268066
tt0268066 could not be retrieved from api
tt4813760
tt4813760 could not be retrieved from api
tt1526001
tt1526001 could not be retrieved from api
tt1243976
tt1243976 could not be retrieved from api
tt2058498
tt3897284
tt3897284 could not be retrieved from api
tt3665690
tt3665690 could not be retrieved from api
tt4132180
tt4132180 could not be retrieved from api
tt0824229
tt0824229 could not be retrieved from api
tt0314990
tt0314990 could not be retrieved from api
tt5423750
tt5423750 could not be retrieved from api
tt5423664
tt5423664 could not be retrieved from api
tt2175125
tt2175125 could not be retrieved from api
tt0404593
tt0404593 could not be retrieved from api
tt4160422
tt4160422 could not be retrieved from api
tt4552562
tt4552562 could not be retrieved from api
tt5804854
tt5804854 could not be retrieved from api
tt0886666
tt0886666 could not be retrieved from api
tt5423824
tt5423824 could not be retrieved from api
tt3500210
tt3500210 could not be retrieved from api
tt0285357
tt0285357 could not be retrieved from api
tt0280234
tt0280234 could not be retrieved from api
tt1863530
tt1863530 could not be retrieved from api
tt0280349
tt0280349 could not be retrieved from api
tt2660922
tt2660922 could not be retrieved from api
tt0292776
tt0292776 could not be retrieved from api
tt4566242
tt0264230
tt0264230 could not be retrieved from api
tt1102523
tt1102523 could not be retrieved from api
tt3333790
tt3333790 could not be retrieved from api
tt0320863
tt0320863 could not be retrieved from api
tt0830848
tt0830848 could not be retrieved from api
tt0939270
tt0939270 could not be retrieved from api
tt1459294
tt1459294 could not be retrieved from api
tt6026132
tt6026132 could not be retrieved from api
tt1443593
tt1443593 could not be retrieved from api
tt0354267
tt0354267 could not be retrieved from api
tt0147749
tt0147749 could not be retrieved from api
tt0161180
tt0161180 could not be retrieved from api
tt4733812
tt4733812 could not be retrieved from api
tt0367362
tt0367362 could not be retrieved from api
tt5626868
tt5626868 could not be retrieved from api
tt7268752
tt7268752 could not be retrieved from api
tt1364951
tt2341819
tt0464767
tt0464767 could not be retrieved from api
tt3550770
tt3550770 could not be retrieved from api
tt6422012
tt6422012 could not be retrieved from api
tt3154248
tt3154248 could not be retrieved from api
tt5016274
tt5016274 could not be retrieved from api
tt1715229
tt1715229 could not be retrieved from api
tt0489426
tt0489426 could not be retrieved from api
tt5798754
tt5798754 could not be retrieved from api
tt2022182
tt2022182 could not be retrieved from api
tt0303564
tt0303564 could not be retrieved from api
tt3462252
tt3462252 could not be retrieved from api
tt0329849
tt0329849 could not be retrieved from api
tt5074180
tt5074180 could not be retrieved from api
tt3900878
tt3900878 could not be retrieved from api
tt3887402
tt3887402 could not be retrieved from api
tt1893088
tt0445890
tt0149408
tt0149408 could not be retrieved from api
tt1360544
tt1360544 could not be retrieved from api
tt1718355
tt1718355 could not be retrieved from api
tt2364950
tt2364950 could not be retrieved from api
tt2279571
tt0285374
tt0285374 could not be retrieved from api
tt5267590
tt5267590 could not be retrieved from api
tt0314993
tt0314993 could not be retrieved from api
tt0300870
tt0300870 could not be retrieved from api
tt7036530
tt7036530 could not be retrieved from api
tt5657014
tt5657014 could not be retrieved from api
tt0149488
tt0149488 could not be retrieved from api
tt1204865
tt1204865 could not be retrieved from api
tt1182860
tt1182860 could not be retrieved from api
tt0423626
tt0423626 could not be retrieved from api
tt4223864
tt4223864 could not be retrieved from api
tt1773440
tt1773440 could not be retrieved from api
tt0872067
tt0872067 could not be retrieved from api
tt0428172
tt0428172 could not be retrieved from api
tt0817379
tt0817379 could not be retrieved from api
tt1210720
tt1210720 could not be retrieved from api
tt3855028
tt3855028 could not be retrieved from api
tt1611594
tt1611594 could not be retrieved from api
tt5822004
tt5822004 could not be retrieved from api
tt6524930
tt6524930 could not be retrieved from api
tt1733734
tt1902032
tt1902032 could not be retrieved from api
tt0466201
tt0466201 could not be retrieved from api
tt1757293
tt1757293 could not be retrieved from api
tt1807575
tt1807575 could not be retrieved from api
tt0332896
tt0332896 could not be retrieved from api
tt3140278
tt3140278 could not be retrieved from api
tt1176297
tt1176297 could not be retrieved from api
tt0285406
tt0285406 could not be retrieved from api
tt6680212
tt6680212 could not be retrieved from api
tt0200336
tt0200336 could not be retrieved from api
tt0385483
tt0385483 could not be retrieved from api
tt3534894
tt3534894 could not be retrieved from api
tt1108281
tt1108281 could not be retrieved from api
tt3855016
tt3855016 could not be retrieved from api
tt0787948
tt0787948 could not be retrieved from api
tt1372153
tt1292967
tt1292967 could not be retrieved from api
tt1466565
tt1466565 could not be retrieved from api
tt0435565
tt0435565 could not be retrieved from api
tt1817054
tt2879822
tt1229266
tt1229266 could not be retrieved from api
tt0364837
tt0364837 could not be retrieved from api
tt0477409
tt0477409 could not be retrieved from api
tt0875097
tt0875097 could not be retrieved from api
tt1227542
tt1227542 could not be retrieved from api
tt1131289
tt1131289 could not be retrieved from api
tt0355135
tt0355135 could not be retrieved from api
tt1418598
tt0290970
tt0290970 could not be retrieved from api
tt0184124
tt0184124 could not be retrieved from api
tt0490736
tt0490736 could not be retrieved from api
tt0439354
tt0439354 could not be retrieved from api
tt1157935
tt1157935 could not be retrieved from api
tt1425641
tt1425641 could not be retrieved from api
tt2830404
tt2830404 could not be retrieved from api
tt0835397
tt0835397 could not be retrieved from api
tt0880581
tt0880581 could not be retrieved from api
tt1078463
tt1078463 could not be retrieved from api
tt0190177
tt1234506
tt1234506 could not be retrieved from api
tt0323463
tt0323463 could not be retrieved from api
tt5047510
tt5338860
tt5168468
tt5168468 could not be retrieved from api
tt0296322
tt0296322 could not be retrieved from api
tt3911254
tt3911254 could not be retrieved from api
tt3827516
tt3827516 could not be retrieved from api
tt0364899
tt0364899 could not be retrieved from api
tt4204032
tt4204032 could not be retrieved from api
tt0259768
tt0259768 could not be retrieved from api
tt0287880
tt0287880 could not be retrieved from api
tt0270763
tt0270763 could not be retrieved from api
tt0846349
tt0846349 could not be retrieved from api
tt2699648
tt2699648 could not be retrieved from api
tt3616368
tt3616368 could not be retrieved from api
tt2672920
tt2672920 could not be retrieved from api
tt1848281
tt0813074
tt0813074 could not be retrieved from api
tt1694422
tt1694422 could not be retrieved from api
tt0472241
tt0472241 could not be retrieved from api
tt0202186
tt0202186 could not be retrieved from api
tt1297366
tt1297366 could not be retrieved from api
tt3919918
tt3919918 could not be retrieved from api
tt1564985
tt1564985 could not be retrieved from api
tt3336800
tt3336800 could not be retrieved from api
tt6839504
tt2114184
tt2254454
tt2254454 could not be retrieved from api
tt1674023
tt0824737
tt0824737 could not be retrieved from api
tt1288431
tt1288431 could not be retrieved from api
tt1705811
tt1705811 could not be retrieved from api
tt0968726
tt0968726 could not be retrieved from api
tt2058840
tt2058840 could not be retrieved from api
tt1971860
tt3857708
tt3857708 could not be retrieved from api
tt0315030
tt0315030 could not be retrieved from api
tt2337185
tt2337185 could not be retrieved from api
tt0775356
tt0775356 could not be retrieved from api
tt0244356
tt0244356 could not be retrieved from api
tt2338400
tt2338400 could not be retrieved from api
tt0220047
tt0220047 could not be retrieved from api
tt0341789
tt0341789 could not be retrieved from api
tt0197151
tt0197151 could not be retrieved from api
tt0222529
tt0222529 could not be retrieved from api
tt6086050
tt6086050 could not be retrieved from api
tt3100634
tt1625263
tt1625263 could not be retrieved from api
tt2289244
tt2289244 could not be retrieved from api
tt1936732
tt0278229
tt0278229 could not be retrieved from api
tt0429438
tt0429438 could not be retrieved from api
tt1410490
tt1410490 could not be retrieved from api
tt5588910
tt5588910 could not be retrieved from api
tt3670858
tt3670858 could not be retrieved from api
tt1197582
tt0397182
tt0397182 could not be retrieved from api
tt1911975
tt1911975 could not be retrieved from api
tt0420366
tt0420366 could not be retrieved from api
tt3079034
tt3079034 could not be retrieved from api
tt0859270
tt0859270 could not be retrieved from api
tt0050070
tt0050070 could not be retrieved from api
tt0300798
tt0300798 could not be retrieved from api
tt5915502
tt5915502 could not be retrieved from api
tt6697244
tt6697244 could not be retrieved from api
tt1776388
tt1776388 could not be retrieved from api
tt0424639
tt0424639 could not be retrieved from api
tt1119204
tt1119204 could not be retrieved from api
tt1744868
tt1744868 could not be retrieved from api
tt1588824
tt1588824 could not be retrieved from api
tt1485389
tt3696798
tt3696798 could not be retrieved from api
tt0301123
tt0301123 could not be retrieved from api
tt1018436
tt1018436 could not be retrieved from api
tt0815776
tt0815776 could not be retrieved from api
tt0407462
tt0407462 could not be retrieved from api
tt0198147
tt0198147 could not be retrieved from api
tt0997412
tt0997412 could not be retrieved from api
tt2288050
tt1612920
tt0402701
tt5047494
tt5047494 could not be retrieved from api
tt5368216
tt5368216 could not be retrieved from api
tt3356610
tt3356610 could not be retrieved from api
tt0491735
tt1454750
tt1454750 could not be retrieved from api
tt5891726
tt5891726 could not be retrieved from api
tt2369946
tt4286824
tt4286824 could not be retrieved from api
tt0476926
tt0476926 could not be retrieved from api
tt5167034
tt5167034 could not be retrieved from api
tt0056759
tt0056759 could not be retrieved from api
tt3622818
tt3622818 could not be retrieved from api
tt0887788
tt0887788 could not be retrieved from api
tt4588620
tt4588620 could not be retrieved from api
tt0258341
tt0258341 could not be retrieved from api
tt0489430
tt0489430 could not be retrieved from api
tt2567210
tt2567210 could not be retrieved from api
tt0990403
tt4674178
tt4674178 could not be retrieved from api
tt0125638
tt0125638 could not be retrieved from api
tt5146640
tt5146640 could not be retrieved from api
tt0196284
tt0196284 could not be retrieved from api
tt3075154
tt3075154 could not be retrieved from api
tt0436003
tt0436003 could not be retrieved from api
tt1538090
tt1538090 could not be retrieved from api
tt1728226
tt1728226 could not be retrieved from api
tt3796070
tt3796070 could not be retrieved from api
tt1381395
tt1381395 could not be retrieved from api
tt0190199
tt0190199 could not be retrieved from api
tt0855213
tt0855213 could not be retrieved from api
tt0358890
tt0358890 could not be retrieved from api
tt3484986
tt3484986 could not be retrieved from api
tt2208507
tt2208507 could not be retrieved from api
tt4896052
tt4896052 could not be retrieved from api
tt6148376
tt0217211
tt0217211 could not be retrieved from api
tt0430836
tt0430836 could not be retrieved from api
tt1429551
tt1291098
tt1291098 could not be retrieved from api
tt0399968
tt0399968 could not be retrieved from api
tt2909920
tt2909920 could not be retrieved from api
tt3164276
tt3164276 could not be retrieved from api
tt1586637
tt4873032
tt0926012
tt0926012 could not be retrieved from api
tt1305560
tt1305560 could not be retrieved from api
tt1291488
tt1291488 could not be retrieved from api
tt0428088
tt0428088 could not be retrieved from api
tt1057469
tt1057469 could not be retrieved from api
tt3807326
tt3807326 could not be retrieved from api
tt3293566
tt0410964
tt1579186
tt0271931
tt6519752
tt1417358
tt4568130
tt1705611
tt2235190
tt0244328
tt0244328 could not be retrieved from api
tt0459155
tt0459155 could not be retrieved from api
tt1890984
tt1890984 could not be retrieved from api
tt0460381
tt0460381 could not be retrieved from api
tt0439069
tt0439069 could not be retrieved from api
tt0329817
tt0329817 could not be retrieved from api
tt1805082
tt1805082 could not be retrieved from api
tt0468985
tt0468985 could not be retrieved from api
tt1071166
tt1071166 could not be retrieved from api
tt1634699
tt1634699 could not be retrieved from api
tt1086761
tt4214468
tt0170930
tt0170930 could not be retrieved from api
tt5937940
tt0305056
tt1024887
tt1024887 could not be retrieved from api
tt1833558
tt7062438
tt7062438 could not be retrieved from api
tt4411548
tt4411548 could not be retrieved from api
tt0105970
tt0105970 could not be retrieved from api
tt0348949
tt0348949 could not be retrieved from api
tt2309197
tt2309197 could not be retrieved from api
tt0327271
tt0327271 could not be retrieved from api
tt1729597
tt1729597 could not be retrieved from api
tt0428108
tt0428108 could not be retrieved from api
tt3144026
tt3144026 could not be retrieved from api
tt0292770
tt0077041
tt1489024
tt0458269
tt1020924
tt0444578
tt0787980
tt0249275
tt1280868
tt0462121
tt3136086
tt1908157
tt0055714
tt0781991
tt0224517
tt0426804
tt0484508
tt0186742
tt0460081
tt0320809
tt0798631
tt3119834
tt3804586
tt0479614
tt0479614 could not be retrieved from api
tt0780447
tt0780447 could not be retrieved from api
tt0123366
tt3481544
tt3975956
tt3975956 could not be retrieved from api
tt5335110
tt0471990
tt0471990 could not be retrieved from api
tt1332074
tt6846846
tt6846846 could not be retrieved from api
tt1259798
tt0381741
tt0381741 could not be retrieved from api
tt2953706
tt1244881
tt6208480
tt6208480 could not be retrieved from api
tt1232190
tt0829040
tt0829040 could not be retrieved from api
tt3859844
tt1761662
tt1761662 could not be retrieved from api
tt2262354
tt0103411
tt0103411 could not be retrieved from api
tt0356281
tt0356281 could not be retrieved from api
tt4628798
tt4628798 could not be retrieved from api
tt0283714
tt1147702
tt1147702 could not be retrieved from api
tt0780444
tt0780444 could not be retrieved from api
tt1981147
tt0756524
tt0312095
tt0260645
tt1728958
tt4688354
tt1296242
tt1062211
tt1500453
tt0358320
tt1118205
tt0480781
tt0303490
tt0278256
tt0812148
tt0892683
tt1562042
tt0218767
tt2265901
tt1456074
tt1978967
tt0313038
tt5437800
tt5437800 could not be retrieved from api
tt2453016
tt5209238
tt5209238 could not be retrieved from api
tt7165310
tt7165310 could not be retrieved from api
tt1277979
tt0362379
tt0362379 could not be retrieved from api
tt0348512
tt0348512 could not be retrieved from api
tt1024814
tt0065343
tt0065343 could not be retrieved from api
tt3976016
tt3976016 could not be retrieved from api
tt1459376
tt1459376 could not be retrieved from api
tt4629950
tt4629950 could not be retrieved from api
tt0443361
tt0443361 could not be retrieved from api
tt1320317
tt1320317 could not be retrieved from api
tt1770959
tt6212410
tt6212410 could not be retrieved from api
tt3731648
tt5872774
tt5872774 could not be retrieved from api
tt4410468
tt0196232
tt0196232 could not be retrieved from api
tt3693866
tt3693866 could not be retrieved from api
tt6295148
tt6295148 could not be retrieved from api
tt0804424
tt0804424 could not be retrieved from api
tt0458252
tt0458252 could not be retrieved from api
tt2933730
tt2933730 could not be retrieved from api
tt5690306
tt5690306 could not be retrieved from api
tt3038492
tt0854912
tt0426740
tt0364787
tt1033281
tt0473416
tt5423592
tt2064427
tt1208634
tt0402660
tt1566044
tt0292845
tt2633208
tt1685317
tt0421158
tt1176154
tt3099832
tt0396337
tt0337790
tt0287847
tt0421343
tt0408364
tt0346300
tt0346300 could not be retrieved from api
tt2908564
tt2908564 could not be retrieved from api
tt0348894
tt6959064
tt6959064 could not be retrieved from api
tt1737565
tt1454730
tt0468999
tt1495163
tt2514488
tt2390003
tt0293725
tt0293725 could not be retrieved from api
tt0092362
tt0092362 could not be retrieved from api
tt0818895
tt0818895 could not be retrieved from api
tt1509653
tt1509653 could not be retrieved from api
tt1809909
tt1809909 could not be retrieved from api
tt1796975
tt1796975 could not be retrieved from api
tt6501522
tt6501522 could not be retrieved from api
tt0424611
tt0424611 could not be retrieved from api
tt0439932
tt0439932 could not be retrieved from api
tt4671004
tt0471048
tt0471048 could not be retrieved from api
tt1156526
tt1156526 could not be retrieved from api
tt0264226
tt0264226 could not be retrieved from api
tt1170222
tt1170222 could not be retrieved from api
tt2689384
tt0295081
tt0295081 could not be retrieved from api
tt4369244
tt4369244 could not be retrieved from api
tt2781594
tt2781594 could not be retrieved from api
tt4662374
tt1105316
tt1105316 could not be retrieved from api
tt3840030
tt3840030 could not be retrieved from api
tt2579722
tt0072546
tt4628790
tt0046590
tt2184509
tt0497854
tt0363323
tt1458207
tt0439356
tt0377146
tt0954318
tt2214505
tt2435530
tt0473419
tt0768151
tt0439365
tt0278177
tt1299440
tt2083701
tt1933836
tt6473824
tt6473824 could not be retrieved from api
tt0187632
tt0187632 could not be retrieved from api
tt4033696
tt0391666
tt0391666 could not be retrieved from api
tt0465344
tt0465344 could not be retrieved from api
tt2170392
tt4390084
tt2189892
tt2189892 could not be retrieved from api
tt6586510
tt6586510 could not be retrieved from api
tt3174316
tt2374870
tt2374870 could not be retrieved from api
tt2366111
tt2111994
tt2111994 could not be retrieved from api
tt4588734
tt4588734 could not be retrieved from api
tt0863047
tt0863047 could not be retrieved from api
tt1495648
tt1579108
tt1579108 could not be retrieved from api
tt1159610
tt0984168
tt0984168 could not be retrieved from api
tt6752226
tt6752226 could not be retrieved from api
tt0856723
tt0856723 could not be retrieved from api
tt0416347
tt0416347 could not be retrieved from api
tt5571740
tt5571740 could not be retrieved from api
tt1552185
tt1552185 could not be retrieved from api
tt3595870
tt1728864
tt1062185
tt0380949
tt1013861
tt0848174
tt0321000
tt1855738
tt0363335
tt0420381
tt1814550
tt1987353
tt0187654
tt1461569
tt1850160
tt0954661
tt0198095
tt4012388
tt0482028
tt0176381
tt0419307
tt1684732
tt5154762
tt3139774
tt0819708
tt0819708 could not be retrieved from api
tt0888280
tt0888280 could not be retrieved from api
tt6021260
tt6021260 could not be retrieved from api
tt0185065
tt0185065 could not be retrieved from api
tt4123482
tt1491299
tt1492090
tt6059298
tt6059298 could not be retrieved from api
tt1826951
tt0273025
tt0273025 could not be retrieved from api
tt1888795
tt1888795 could not be retrieved from api
tt1821879
tt1821879 could not be retrieved from api
tt2497788
tt0476038
tt0476038 could not be retrieved from api
tt1830924
tt1830924 could not be retrieved from api
tt1368470
tt1368470 could not be retrieved from api
tt1361721
tt1361721 could not be retrieved from api
tt2647792
tt2647792 could not be retrieved from api
tt3148194
tt0302163
tt0302163 could not be retrieved from api
tt5515342
tt0292859
tt0292859 could not be retrieved from api
tt0243082
tt0243082 could not be retrieved from api
tt4654650
tt4654650 could not be retrieved from api
tt0298682
tt0298682 could not be retrieved from api
tt1534856
tt1534856 could not be retrieved from api
tt3097134
tt3097134 could not be retrieved from api
tt2582840
tt2582840 could not be retrieved from api
tt4605154
tt1478217
tt1478217 could not be retrieved from api
tt0374366
tt1631948
tt0368494
tt1721347
tt5319670
tt1684855
tt5209280
tt6217260
tt6842890
tt5040090
tt3501210
tt0367323
tt0397012
tt0954837
tt1784056
tt3228548
tt0861753
tt0933898
tt0433705
tt0287845
tt0329816
tt0329816 could not be retrieved from api
tt2815342
tt3548386
tt3548386 could not be retrieved from api
tt0410958
tt0410958 could not be retrieved from api
tt0057740
tt0057740 could not be retrieved from api
tt5583124
tt5583124 could not be retrieved from api
tt1440045
tt1440045 could not be retrieved from api
tt0810737
tt0810737 could not be retrieved from api
tt0989753
tt0989753 could not be retrieved from api
tt1313075
tt1313075 could not be retrieved from api
tt1073528
tt1073528 could not be retrieved from api
tt0310516
tt0310516 could not be retrieved from api
tt1642103
tt1642103 could not be retrieved from api
tt0448973
tt0448973 could not be retrieved from api
tt0302098
tt0302098 could not be retrieved from api
tt0805368
tt0805368 could not be retrieved from api
tt1124662
tt1124662 could not be retrieved from api
tt0324891
tt0324891 could not be retrieved from api
tt0423631
tt0423631 could not be retrieved from api
tt2226096
tt2226096 could not be retrieved from api
tt0773264
tt1798695
tt1307083
tt4845734
tt0046641
tt0046641 could not be retrieved from api
tt1519575
tt1519575 could not be retrieved from api
tt0853078
tt0853078 could not be retrieved from api
tt0118423
tt0118423 could not be retrieved from api
tt0284767
tt4052124
tt4052124 could not be retrieved from api
tt0878801
tt3703500
# Oops, We've hit the API to hard. A second attempt to pull low rated show information
# will be needed, with a time delay to stay within API limitations.
# This shape is misleading, as many of the rows simply contain a message that the API limit
# had been exceeded
losers.shape
# This is accurate, 235 shows from the top show list were obtained
shows.shape
DO_NOT_RUN = True # Be sure to check the file name to write before enabling execution on this block
if not DO_NOT_RUN:
pickle.dump( losers, open( "save_losers_df.p", "wb" ) )
# read data back in from the saved file
losers2 = pickle.load( open( "save_losers_df.p", "rb" ) )
This is the start of a second attempt to pull more TV shows with low ratings
This is needed. After the first pull, and after cleanup, there were only 10 Shows left in the low rating category with complete information. The cells below collect more data from the API for additional low rated shows.
losers.loc[0:9]['externals']
0 {u'thetvdb': 283995, u'tvrage': 40425, u'imdb'...
1 {u'thetvdb': 299234, u'tvrage': 50418, u'imdb'...
2 {u'thetvdb': 118021, u'tvrage': None, u'imdb':...
3 {u'thetvdb': 274705, u'tvrage': 31580, u'imdb'...
4 {u'thetvdb': 246161, u'tvrage': None, u'imdb':...
5 {u'thetvdb': 75638, u'tvrage': None, u'imdb': ...
6 {u'thetvdb': 260183, u'tvrage': 31024, u'imdb'...
7 {u'thetvdb': None, u'tvrage': None, u'imdb': u...
8 {u'thetvdb': 299688, u'tvrage': None, u'imdb':...
9 {u'thetvdb': 222481, u'tvrage': None, u'imdb':...
Name: externals, dtype: object
# In the first attempt, there were a number of shows where data was not returned becuase of two many api calls
# in quick succession. In order to re-submit those show ids, it is necessary to get a list of ids that were
# returned successfully, and then to remove them from the original list of ids before resubmitting.
# losers_pulled is a list of ids that were successful on the previous attempt.
losers_pulled = []
no_imdb_at_idx = []
for i in range(len(losers)):
try:
losers_pulled.append(losers.loc[i,'externals']['imdb'])
except:
no_imdb_at_idx.append(i)
print no_imdb_at_idx
print
print losers_pulled
print len(losers_pulled)
[11, 35, 36, 37, 38, 39, 40, 41, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 228]
[u'tt2058498', u'tt4566242', u'tt1364951', u'tt2341819', u'tt1893088', u'tt0445890', u'tt2279571', u'tt1733734', u'tt1372153', u'tt1817054', u'tt2879822', u'tt0190177', u'tt5047510', u'tt5338860', u'tt1848281', u'tt6839504', u'tt2114184', u'tt1674023', u'tt1971860', u'tt3100634', u'tt1936732', u'tt1197582', u'tt1485389', u'tt2288050', u'tt1612920', u'tt0402701', u'tt0491735', u'tt2369946', u'tt0990403', u'tt6148376', u'tt1429551', u'tt1586637', u'tt4873032', u'tt3293566', u'tt2235190', u'tt1086761', u'tt4214468', u'tt5937940', u'tt0305056', u'tt1833558', u'tt0123366', u'tt3481544', u'tt5335110', u'tt1332074', u'tt1259798', u'tt2953706', u'tt1244881', u'tt1232190', u'tt3859844', u'tt2262354', u'tt0283714', u'tt0313038', u'tt2453016', u'tt1277979', u'tt1024814', u'tt1770959', u'tt3731648', u'tt4410468', u'tt0348894', u'tt1737565', u'tt1454730', u'tt0468999', u'tt1495163', u'tt2514488', u'tt2390003', u'tt4671004', u'tt2689384', u'tt4662374', u'tt1299440', u'tt2083701', u'tt1933836', u'tt4033696', u'tt2170392', u'tt4390084', u'tt3174316', u'tt2366111', u'tt1495648', u'tt1159610', u'tt4123482', u'tt1491299', u'tt1492090', u'tt1826951', u'tt2497788', u'tt3148194', u'tt5515342', u'tt4605154', u'tt2815342', u'tt0773264', u'tt1798695', u'tt1307083', u'tt4845734', u'tt0284767', u'tt0878801']
93
# There were that do not even include their own imdb number, and indicator that the pull was unsuccessful
# While a few of these might have been successful but have only limited data, most are unusuable.
# Thus all will be re-requested at a slower rate and any duplicates removed when the data is merged.
print len(no_imdb_at_idx)
# This generates a list of the original requests that were not successfully returned from the api.
# First the will be requested again, using a time delay to avoid requesting more than the server
# will willingly return. They will also be batched in groups of 100 ids
missing_losers = [x for x in loser_list if x not in losers_pulled]
missing_losers
['tt0465347',
'tt4427122',
'tt1015682',
'tt2505738',
'tt2402465',
'tt0278236',
'tt0268066',
'tt4813760',
'tt1526001',
'tt1243976',
'tt3897284',
'tt3665690',
'tt4132180',
'tt0824229',
'tt0314990',
'tt5423750',
'tt5423664',
'tt2175125',
'tt0404593',
'tt4160422',
'tt4552562',
'tt5804854',
'tt0886666',
'tt5423824',
'tt3500210',
'tt0285357',
'tt0280234',
'tt1863530',
'tt0280349',
'tt2660922',
'tt0292776',
'tt0264230',
'tt1102523',
'tt3333790',
'tt0320863',
'tt0830848',
'tt0939270',
'tt1459294',
'tt6026132',
'tt1443593',
'tt0354267',
'tt0147749',
'tt0161180',
'tt4733812',
'tt0367362',
'tt5626868',
'tt7268752',
'tt0464767',
'tt3550770',
'tt6422012',
'tt3154248',
'tt5016274',
'tt1715229',
'tt0489426',
'tt5798754',
'tt2022182',
'tt0303564',
'tt3462252',
'tt0329849',
'tt5074180',
'tt3900878',
'tt3887402',
'tt0149408',
'tt1360544',
'tt1718355',
'tt2364950',
'tt0285374',
'tt5267590',
'tt0314993',
'tt0300870',
'tt7036530',
'tt5657014',
'tt0149488',
'tt1204865',
'tt1182860',
'tt0423626',
'tt4223864',
'tt1773440',
'tt0872067',
'tt0428172',
'tt0817379',
'tt1210720',
'tt3855028',
'tt1611594',
'tt5822004',
'tt6524930',
'tt1902032',
'tt0466201',
'tt1757293',
'tt1807575',
'tt0332896',
'tt3140278',
'tt1176297',
'tt0285406',
'tt6680212',
'tt0200336',
'tt0385483',
'tt3534894',
'tt1108281',
'tt3855016',
'tt0787948',
'tt1292967',
'tt1466565',
'tt0435565',
'tt1229266',
'tt0364837',
'tt0477409',
'tt0875097',
'tt1227542',
'tt1131289',
'tt0355135',
'tt1418598',
'tt0290970',
'tt0184124',
'tt0490736',
'tt0439354',
'tt1157935',
'tt1425641',
'tt2830404',
'tt0835397',
'tt0880581',
'tt1078463',
'tt1234506',
'tt0323463',
'tt5168468',
'tt0296322',
'tt3911254',
'tt3827516',
'tt0364899',
'tt4204032',
'tt0259768',
'tt0287880',
'tt0270763',
'tt0846349',
'tt2699648',
'tt3616368',
'tt2672920',
'tt0813074',
'tt1694422',
'tt0472241',
'tt0202186',
'tt1297366',
'tt3919918',
'tt1564985',
'tt3336800',
'tt2254454',
'tt0824737',
'tt1288431',
'tt1705811',
'tt0968726',
'tt2058840',
'tt3857708',
'tt0315030',
'tt2337185',
'tt0775356',
'tt0244356',
'tt2338400',
'tt0220047',
'tt0341789',
'tt0197151',
'tt0222529',
'tt6086050',
'tt1625263',
'tt2289244',
'tt0278229',
'tt0429438',
'tt1410490',
'tt5588910',
'tt3670858',
'tt0397182',
'tt1911975',
'tt0420366',
'tt3079034',
'tt0859270',
'tt0050070',
'tt0300798',
'tt5915502',
'tt6697244',
'tt1776388',
'tt0424639',
'tt1119204',
'tt1744868',
'tt1588824',
'tt3696798',
'tt0301123',
'tt1018436',
'tt0815776',
'tt0407462',
'tt0198147',
'tt0997412',
'tt5047494',
'tt5368216',
'tt3356610',
'tt1454750',
'tt5891726',
'tt4286824',
'tt0476926',
'tt5167034',
'tt0056759',
'tt3622818',
'tt0887788',
'tt4588620',
'tt0258341',
'tt0489430',
'tt2567210',
'tt4674178',
'tt0125638',
'tt5146640',
'tt0196284',
'tt3075154',
'tt0436003',
'tt1538090',
'tt1728226',
'tt3796070',
'tt1381395',
'tt0190199',
'tt0855213',
'tt0358890',
'tt3484986',
'tt2208507',
'tt4896052',
'tt0217211',
'tt0430836',
'tt1291098',
'tt0399968',
'tt2909920',
'tt3164276',
'tt0926012',
'tt1305560',
'tt1291488',
'tt0428088',
'tt1057469',
'tt3807326',
'tt0410964',
'tt1579186',
'tt0271931',
'tt6519752',
'tt1417358',
'tt4568130',
'tt1705611',
'tt0244328',
'tt0459155',
'tt1890984',
'tt0460381',
'tt0439069',
'tt0329817',
'tt1805082',
'tt0468985',
'tt1071166',
'tt1634699',
'tt0170930',
'tt1024887',
'tt7062438',
'tt4411548',
'tt0105970',
'tt0348949',
'tt2309197',
'tt0327271',
'tt1729597',
'tt0428108',
'tt3144026',
'tt0292770',
'tt0077041',
'tt1489024',
'tt0458269',
'tt1020924',
'tt0444578',
'tt0787980',
'tt0249275',
'tt1280868',
'tt0462121',
'tt3136086',
'tt1908157',
'tt0055714',
'tt0781991',
'tt0224517',
'tt0426804',
'tt0484508',
'tt0186742',
'tt0460081',
'tt0320809',
'tt0798631',
'tt3119834',
'tt3804586',
'tt0479614',
'tt0780447',
'tt3975956',
'tt0471990',
'tt6846846',
'tt0381741',
'tt6208480',
'tt0829040',
'tt1761662',
'tt0103411',
'tt0356281',
'tt4628798',
'tt1147702',
'tt0780444',
'tt1981147',
'tt0756524',
'tt0312095',
'tt0260645',
'tt1728958',
'tt4688354',
'tt1296242',
'tt1062211',
'tt1500453',
'tt0358320',
'tt1118205',
'tt0480781',
'tt0303490',
'tt0278256',
'tt0812148',
'tt0892683',
'tt1562042',
'tt0218767',
'tt2265901',
'tt1456074',
'tt1978967',
'tt5437800',
'tt5209238',
'tt7165310',
'tt0362379',
'tt0348512',
'tt0065343',
'tt3976016',
'tt1459376',
'tt4629950',
'tt0443361',
'tt1320317',
'tt6212410',
'tt5872774',
'tt0196232',
'tt3693866',
'tt6295148',
'tt0804424',
'tt0458252',
'tt2933730',
'tt5690306',
'tt3038492',
'tt0854912',
'tt0426740',
'tt0364787',
'tt1033281',
'tt0473416',
'tt5423592',
'tt2064427',
'tt1208634',
'tt0402660',
'tt1566044',
'tt0292845',
'tt2633208',
'tt1685317',
'tt0421158',
'tt1176154',
'tt3099832',
'tt0396337',
'tt0337790',
'tt0287847',
'tt0421343',
'tt0408364',
'tt0346300',
'tt2908564',
'tt6959064',
'tt0293725',
'tt0092362',
'tt0818895',
'tt1509653',
'tt1809909',
'tt1796975',
'tt6501522',
'tt0424611',
'tt0439932',
'tt0471048',
'tt1156526',
'tt0264226',
'tt1170222',
'tt0295081',
'tt4369244',
'tt2781594',
'tt1105316',
'tt3840030',
'tt2579722',
'tt0072546',
'tt4628790',
'tt0046590',
'tt2184509',
'tt0497854',
'tt0363323',
'tt1458207',
'tt0439356',
'tt0377146',
'tt0954318',
'tt2214505',
'tt2435530',
'tt0473419',
'tt0768151',
'tt0439365',
'tt0278177',
'tt6473824',
'tt0187632',
'tt0391666',
'tt0465344',
'tt2189892',
'tt6586510',
'tt2374870',
'tt2111994',
'tt4588734',
'tt0863047',
'tt1579108',
'tt0984168',
'tt6752226',
'tt0856723',
'tt0416347',
'tt5571740',
'tt1552185',
'tt3595870',
'tt1728864',
'tt1062185',
'tt0380949',
'tt1013861',
'tt0848174',
'tt0321000',
'tt1855738',
'tt0363335',
'tt0420381',
'tt1814550',
'tt1987353',
'tt0187654',
'tt1461569',
'tt1850160',
'tt0954661',
'tt0198095',
'tt4012388',
'tt0482028',
'tt0176381',
'tt0419307',
'tt1684732',
'tt5154762',
'tt3139774',
'tt0819708',
'tt0888280',
'tt6021260',
'tt0185065',
'tt6059298',
'tt0273025',
'tt1888795',
'tt1821879',
'tt0476038',
'tt1830924',
'tt1368470',
'tt1361721',
'tt2647792',
'tt0302163',
'tt0292859',
'tt0243082',
'tt4654650',
'tt0298682',
'tt1534856',
'tt3097134',
'tt2582840',
'tt1478217',
'tt0374366',
'tt1631948',
'tt0368494',
'tt1721347',
'tt5319670',
'tt1684855',
'tt5209280',
'tt6217260',
'tt6842890',
'tt5040090',
'tt3501210',
'tt0367323',
'tt0397012',
'tt0954837',
'tt1784056',
'tt3228548',
'tt0861753',
'tt0933898',
'tt0433705',
'tt0287845',
'tt0329816',
'tt3548386',
'tt0410958',
'tt0057740',
'tt5583124',
'tt1440045',
'tt0810737',
'tt0989753',
'tt1313075',
'tt1073528',
'tt0310516',
'tt1642103',
'tt0448973',
'tt0302098',
'tt0805368',
'tt1124662',
'tt0324891',
'tt0423631',
'tt2226096',
'tt0046641',
'tt1519575',
'tt0853078',
'tt0118423',
'tt4052124',
'tt3703500']
# This processes the oringinal list of 600 ids, minus the ones that were successfully pulled,
# into groups of 100 + 7 in last list
# break up the missing list into groups of 100
subset_loser_list = []
print len(missing_losers)
for i in range(len(missing_losers)/100):
temp_list = []
for j in range(100):
temp_list.append(missing_losers[i*100 + j])
subset_loser_list.append(temp_list)
# get last 7
for j in range(500, len(missing_losers)):
temp_list = []
for j in range(500, len(missing_losers)):
temp_list.append(missing_losers[j])
# After reprocessing the first list of ids a 2nd time, there are still not enough samples of low rated shows
# A third list of 600 low rated shows was scraped from IMDB, and this list is broken into subsets of 100 here
subset_loser_list2 = []
print len(loser_list)
for i in range(len(loser_list)/100):
temp_list = []
for j in range(100):
temp_list.append(loser_list[i*100 + j])
subset_loser_list2.append(temp_list)
['tt0773264',
'tt1798695',
'tt1307083',
'tt4845734',
'tt0046641',
'tt1519575',
'tt0853078',
'tt0118423',
'tt0284767',
'tt4052124',
'tt0878801',
'tt3703500',
'tt1105170',
'tt4363582',
'tt3155428',
'tt0362350',
'tt0287196',
'tt2766052',
'tt0405545',
'tt0262975',
'tt0367278',
'tt7134262',
'tt1695352',
'tt0421470',
'tt2466890',
'tt0343305',
'tt1002739',
'tt1615697',
'tt0274262',
'tt0465320',
'tt1388381',
'tt0358889',
'tt1085789',
'tt1011591',
'tt0364804',
'tt1489335',
'tt3612584',
'tt0363377',
'tt0111930',
'tt0401913',
'tt0808086',
'tt0309212',
'tt5464192',
'tt0080250',
'tt4533338',
'tt4741696',
'tt1922810',
'tt1793868',
'tt4789316',
'tt0185054',
'tt1079622',
'tt1786048',
'tt0790508',
'tt1716372',
'tt0295098',
'tt3409706',
'tt0222574',
'tt2171325',
'tt0442643',
'tt2142117',
'tt0371433',
'tt0138244',
'tt1002010',
'tt0495557',
'tt1811817',
'tt5529996',
'tt1352053',
'tt0439346',
'tt0940147',
'tt3075138',
'tt1974439',
'tt2693842',
'tt0092325',
'tt6772826',
'tt1563069',
'tt0489598',
'tt0142055',
'tt1566154',
'tt0338592',
'tt0167515',
'tt2330327',
'tt1576464',
'tt2389845',
'tt0186747',
'tt0355096',
'tt1821877',
'tt0112033',
'tt1792654',
'tt0472243',
'tt6453018',
'tt3648886',
'tt1599374',
'tt2946482',
'tt4672020',
'tt1016283',
'tt2649480',
'tt1229945',
'tt2390606',
'tt1876612',
'tt0140732']
# This block calls the API. It is run repeatedly with each new sublist of 100 show ids, sleeping 10
# seconds between each request. There is a do not run flag that will prevent running this block if the
# notebook is restarted. The first time it was executed, a new dataframe called "more_losers" was initialized,
# and then commented out for subsequent executions so the data returned in eacn subsequent data request will
# be appended to the bottom of the dataframe.
# After collection is complete, set flag to prevent running this block unnecessarily if notebook is restarted
import time
DO_NOT_RUN = True
if not DO_NOT_RUN:
# responses = []
# more_losers = pd.DataFrame()
for loser_id in subset_loser_list2[0]: # change the index and re-run to accesses each set of 100 ids
time.sleep(10)
try:
# Get the tv show info from the api
url = "http://api.tvmaze.com/lookup/shows?imdb=" + loser_id
r = requests.get(url)
# convert the return data to a dictionary
json_data = r.json()
# load a temp datafram with the dictionary, then append to the composite dataframe
temp_df = pd.DataFrame.from_dict(json_data, orient='index', dtype=None)
ttemp_df = temp_df.T # Was not able to load json in column orientation, so must transpose
more_losers = more_losers.append(ttemp_df, ignore_index=True)
stat = ''
except:
stat = 'failed'
print loser_id, stat, r.status_code
res = [loser_id, stat, r.status_code]
responses.append(res)
losers.head()
tt0773264 200
tt1798695 200
tt1307083 200
tt4845734 200
tt0046641 failed 404
tt1519575 failed 404
tt0853078 failed 404
tt0118423 failed 404
tt0284767 200
tt4052124 failed 404
tt0878801 200
tt3703500 200
tt1105170 failed 404
tt4363582 failed 404
tt3155428 200
tt0362350 failed 404
tt0287196 200
tt2766052 200
tt0405545 failed 404
tt0262975 200
tt0367278 failed 404
tt7134262 failed 404
tt1695352 failed 404
tt0421470 failed 404
tt2466890 failed 404
tt0343305 failed 404
tt1002739 failed 404
tt1615697 failed 404
tt0274262 failed 404
tt0465320 failed 404
tt1388381 200
tt0358889 200
tt1085789 failed 404
tt1011591 200
tt0364804 failed 404
tt1489335 failed 404
tt3612584 200
tt0363377 failed 404
tt0111930 failed 404
tt0401913 failed 404
tt0808086 failed 404
tt0309212 failed 404
tt5464192 200
tt0080250 failed 404
tt4533338 failed 404
tt4741696 200
tt1922810 failed 404
tt1793868 failed 404
tt4789316 failed 404
tt0185054 failed 404
tt1079622 failed 404
tt1786048 failed 404
tt0790508 failed 404
tt1716372 failed 404
tt0295098 failed 404
tt3409706 failed 404
tt0222574 failed 404
tt2171325 failed 404
tt0442643 failed 404
tt2142117 failed 404
tt0371433 failed 404
tt0138244 failed 404
tt1002010 failed 404
tt0495557 failed 404
tt1811817 failed 404
tt5529996 failed 404
tt1352053 failed 404
tt0439346 failed 404
tt0940147 failed 404
tt3075138 failed 404
tt1974439 200
tt2693842 failed 404
tt0092325 200
tt6772826 200
tt1563069 200
tt0489598 200
tt0142055 failed 404
tt1566154 200
tt0338592 200
tt0167515 200
tt2330327 200
tt1576464 failed 404
tt2389845 failed 404
tt0186747 200
tt0355096 failed 404
tt1821877 200
tt0112033 failed 404
tt1792654 failed 404
tt0472243 failed 404
tt6453018 failed 404
tt3648886 failed 404
tt1599374 200
tt2946482 200
tt4672020 failed 404
tt1016283 failed 404
tt2649480 200
tt1229945 200
tt2390606 failed 404
tt1876612 200
tt0140732 failed 404
for i in range(len(more_losers)):
print more_losers.loc[i, 'externals']
{u'thetvdb': 279947, u'tvrage': 37045, u'imdb': u'tt3595870'}
{u'thetvdb': None, u'tvrage': 13173, u'imdb': u'tt0848174'}
{u'thetvdb': 72157, u'tvrage': None, u'imdb': u'tt0374366'}
{u'thetvdb': 218241, u'tvrage': None, u'imdb': u'tt1684855'}
{u'thetvdb': 327908, u'tvrage': None, u'imdb': u'tt6842890'}
{u'thetvdb': 279810, u'tvrage': None, u'imdb': u'tt3501210'}
{u'thetvdb': 283658, u'tvrage': None, u'imdb': u'tt0367323'}
{u'thetvdb': 271341, u'tvrage': 33650, u'imdb': u'tt2633208'}
{u'thetvdb': 260677, u'tvrage': None, u'imdb': u'tt2579722'}
{u'thetvdb': 77616, u'tvrage': None, u'imdb': u'tt0072546'}
{u'thetvdb': 74419, u'tvrage': None, u'imdb': u'tt0458269'}
{u'thetvdb': None, u'tvrage': None, u'imdb': u'tt0249275'}
{u'thetvdb': 282527, u'tvrage': 42189, u'imdb': u'tt2815184'}
{u'thetvdb': 246631, u'tvrage': None, u'imdb': u'tt1753229'}
{u'thetvdb': 82500, u'tvrage': None, u'imdb': u'tt1240534'}
{u'thetvdb': 206381, u'tvrage': 26873, u'imdb': u'tt1999642'}
{u'thetvdb': 284259, u'tvrage': None, u'imdb': u'tt3784176'}
{u'thetvdb': 250186, u'tvrage': None, u'imdb': u'tt1958848'}
{u'thetvdb': 320679, u'tvrage': None, u'imdb': u'tt5684430'}
{u'thetvdb': 74181, u'tvrage': 6494, u'imdb': u'tt0134269'}
{u'thetvdb': 84159, u'tvrage': 19672, u'imdb': u'tt1252370'}
{u'thetvdb': 300105, u'tvrage': 48178, u'imdb': u'tt3824018'}
{u'thetvdb': 264850, u'tvrage': None, u'imdb': u'tt2555880'}
{u'thetvdb': 277020, u'tvrage': 35629, u'imdb': u'tt3310544'}
{u'thetvdb': 254524, u'tvrage': 31887, u'imdb': u'tt2125758'}
{u'thetvdb': 271916, u'tvrage': None, u'imdb': u'tt1973047'}
{u'thetvdb': 82005, u'tvrage': None, u'imdb': u'tt0934701'}
{u'thetvdb': 250472, u'tvrage': None, u'imdb': u'tt2059031'}
{u'thetvdb': 81491, u'tvrage': None, u'imdb': u'tt1056536'}
{u'thetvdb': 137691, u'tvrage': None, u'imdb': u'tt1618950'}
{u'thetvdb': 74395, u'tvrage': 3883, u'imdb': u'tt0115206'}
{u'thetvdb': 298860, u'tvrage': 50010, u'imdb': u'tt4575056'}
{u'thetvdb': 269115, u'tvrage': 33511, u'imdb': u'tt2889104'}
{u'thetvdb': 285008, u'tvrage': None, u'imdb': u'tt2644204'}
{u'thetvdb': 82237, u'tvrage': None, u'imdb': u'tt1210781'}
{u'thetvdb': 314998, u'tvrage': None, u'imdb': u'tt0048898'}
{u'thetvdb': 276337, u'tvrage': None, u'imdb': u'tt3398108'}
{u'thetvdb': 221621, u'tvrage': None, u'imdb': u'tt1252620'}
{u'thetvdb': 269059, u'tvrage': 35857, u'imdb': u'tt2901828'}
{u'thetvdb': 273303, u'tvrage': 35560, u'imdb': u'tt3006666'}
{u'thetvdb': 260473, u'tvrage': 30918, u'imdb': u'tt2197994'}
{u'thetvdb': 83313, u'tvrage': None, u'imdb': u'tt1263594'}
{u'thetvdb': 80117, u'tvrage': 7218, u'imdb': u'tt0497079'}
{u'thetvdb': 174991, u'tvrage': 25843, u'imdb': u'tt1755893'}
{u'thetvdb': 71424, u'tvrage': None, u'imdb': u'tt0329824'}
{u'thetvdb': 258632, u'tvrage': 31545, u'imdb': u'tt2245937'}
{u'thetvdb': 259235, u'tvrage': None, u'imdb': u'tt2147632'}
{u'thetvdb': 297209, u'tvrage': 38100, u'imdb': u'tt3218114'}
{u'thetvdb': 185651, u'tvrage': None, u'imdb': u'tt1583417'}
{u'thetvdb': 250370, u'tvrage': 28934, u'imdb': u'tt1963853'}
{u'thetvdb': 129051, u'tvrage': None, u'imdb': u'tt1520150'}
{u'thetvdb': 76370, u'tvrage': None, u'imdb': u'tt0236907'}
{u'thetvdb': 316174, u'tvrage': None, u'imdb': u'tt5865052'}
{u'thetvdb': 82304, u'tvrage': 19011, u'imdb': u'tt1231448'}
{u'thetvdb': 289640, u'tvrage': 46963, u'imdb': u'tt4287478'}
{u'thetvdb': 249750, u'tvrage': None, u'imdb': u'tt1874006'}
{u'thetvdb': 250959, u'tvrage': 28442, u'imdb': u'tt2006560'}
{u'thetvdb': 281375, u'tvrage': 38313, u'imdb': u'tt3565412'}
{u'thetvdb': 274414, u'tvrage': None, u'imdb': u'tt3396736'}
{u'thetvdb': 271820, u'tvrage': None, u'imdb': u'tt0855313'}
{u'thetvdb': 250955, u'tvrage': None, u'imdb': u'tt2309561'}
{u'thetvdb': 273130, u'tvrage': 36774, u'imdb': u'tt3136814'}
{u'thetvdb': 84669, u'tvrage': 18525, u'imdb': u'tt1191056'}
{u'thetvdb': 74697, u'tvrage': 3348, u'imdb': u'tt0235917'}
{u'thetvdb': 76708, u'tvrage': None, u'imdb': u'tt0111892'}
{u'thetvdb': 266934, u'tvrage': None, u'imdb': u'tt2643770'}
{u'thetvdb': 79896, u'tvrage': None, u'imdb': u'tt0423657'}
{u'thetvdb': 303252, u'tvrage': None, u'imdb': u'tt5327970'}
{u'thetvdb': 256806, u'tvrage': None, u'imdb': u'tt2190731'}
{u'thetvdb': 78409, u'tvrage': None, u'imdb': u'tt0101041'}
{u'thetvdb': 274820, u'tvrage': None, u'imdb': u'tt3317020'}
{u'thetvdb': 296474, u'tvrage': 45813, u'imdb': u'tt4732076'}
{u'thetvdb': 285651, u'tvrage': 41593, u'imdb': u'tt3828162'}
{u'thetvdb': 315767, u'tvrage': None, u'imdb': u'tt5819414'}
{u'thetvdb': 287534, u'tvrage': 42884, u'imdb': u'tt4180738'}
{u'thetvdb': 76621, u'tvrage': None, u'imdb': u'tt0300802'}
{u'thetvdb': 280683, u'tvrage': 34278, u'imdb': u'tt2649738'}
{u'thetvdb': 280256, u'tvrage': 41644, u'imdb': u'tt3181412'}
{u'thetvdb': 79496, u'tvrage': 2677, u'imdb': u'tt0382400'}
{u'thetvdb': 271514, u'tvrage': None, u'imdb': u'tt2168240'}
{u'thetvdb': 271826, u'tvrage': None, u'imdb': u'tt2560966'}
{u'thetvdb': None, u'tvrage': None, u'imdb': u'tt0375440'}
{u'thetvdb': 282253, u'tvrage': 44602, u'imdb': u'tt4081326'}
{u'thetvdb': None, u'tvrage': None, u'imdb': u'tt6664486'}
{u'thetvdb': 70734, u'tvrage': 14443, u'imdb': u'tt0247094'}
{u'thetvdb': 70852, u'tvrage': 5323, u'imdb': u'tt0320969'}
{u'thetvdb': 267185, u'tvrage': None, u'imdb': u'tt2720144'}
{u'thetvdb': 265320, u'tvrage': 33976, u'imdb': u'tt2287380'}
{u'thetvdb': 252485, u'tvrage': None, u'imdb': u'tt2010634'}
{u'thetvdb': 271722, u'tvrage': 36787, u'imdb': u'tt3084090'}
{u'thetvdb': 260126, u'tvrage': 30877, u'imdb': u'tt2392683'}
{u'thetvdb': 251033, u'tvrage': 28408, u'imdb': u'tt1628058'}
{u'thetvdb': None, u'tvrage': None, u'imdb': u'tt1837169'}
{u'thetvdb': 260341, u'tvrage': 31462, u'imdb': u'tt2404111'}
{u'thetvdb': 89831, u'tvrage': 22647, u'imdb': u'tt1411598'}
{u'thetvdb': 70609, u'tvrage': 5102, u'imdb': u'tt0106123'}
{u'thetvdb': 245071, u'tvrage': 26645, u'imdb': u'tt1740718'}
{u'thetvdb': 73230, u'tvrage': 6188, u'imdb': u'tt0362153'}
{u'thetvdb': 163671, u'tvrage': None, u'imdb': u'tt1637756'}
{u'thetvdb': 259478, u'tvrage': 31194, u'imdb': u'tt2328067'}
{u'thetvdb': 294774, u'tvrage': None, u'imdb': u'tt0057741'}
{u'thetvdb': 282993, u'tvrage': None, u'imdb': u'tt1261356'}
{u'thetvdb': 268795, u'tvrage': 36420, u'imdb': u'tt2559390'}
{u'thetvdb': 72048, u'tvrage': 4056, u'imdb': u'tt0083433'}
{u'thetvdb': 256513, u'tvrage': 31344, u'imdb': u'tt2330453'}
{u'thetvdb': None, u'tvrage': None, u'imdb': u'tt0804423'}
{u'thetvdb': 159351, u'tvrage': None, u'imdb': u'tt1118131'}
{u'thetvdb': 300384, u'tvrage': None, u'imdb': u'tt4016700'}
{u'thetvdb': 264239, u'tvrage': None, u'imdb': u'tt0950199'}
{u'thetvdb': 106801, u'tvrage': None, u'imdb': u'tt1477137'}
{u'thetvdb': 87131, u'tvrage': None, u'imdb': u'tt1176156'}
{u'thetvdb': 173981, u'tvrage': None, u'imdb': u'tt1545453'}
{u'thetvdb': None, u'tvrage': None, u'imdb': u'tt1240983'}
{u'thetvdb': 264762, u'tvrage': 31404, u'imdb': u'tt1415000'}
{u'thetvdb': 72180, u'tvrage': None, u'imdb': u'tt0144701'}
{u'thetvdb': 307473, u'tvrage': None, u'imdb': u'tt4718304'}
{u'thetvdb': 147701, u'tvrage': None, u'imdb': u'tt1095213'}
{u'thetvdb': 98371, u'tvrage': None, u'imdb': u'tt1453090'}
{u'thetvdb': 72141, u'tvrage': None, u'imdb': u'tt0168372'}
{u'thetvdb': 75567, u'tvrage': 12949, u'imdb': u'tt0425725'}
{u'thetvdb': 275787, u'tvrage': None, u'imdb': u'tt3300126'}
{u'thetvdb': 308457, u'tvrage': 51439, u'imdb': u'tt5459976'}
{u'thetvdb': 285286, u'tvrage': 44525, u'imdb': u'tt4041694'}
{u'thetvdb': 261287, u'tvrage': 32847, u'imdb': u'tt2322264'}
{u'thetvdb': 250325, u'tvrage': None, u'imdb': u'tt1441005'}
{u'thetvdb': 72133, u'tvrage': None, u'imdb': u'tt0365991'}
{u'thetvdb': 72488, u'tvrage': None, u'imdb': u'tt0364807'}
{u'thetvdb': 149371, u'tvrage': 25246, u'imdb': u'tt1591375'}
{u'thetvdb': 291820, u'tvrage': None, u'imdb': u'tt3562462'}
{u'thetvdb': 96071, u'tvrage': None, u'imdb': u'tt1372127'}
{u'thetvdb': 287516, u'tvrage': None, u'imdb': u'tt2088493'}
{u'thetvdb': 295059, u'tvrage': 48857, u'imdb': u'tt4658248'}
{u'thetvdb': 250280, u'tvrage': None, u'imdb': u'tt1973659'}
{u'thetvdb': 272357, u'tvrage': None, u'imdb': u'tt2849552'}
{u'thetvdb': 282130, u'tvrage': None, u'imdb': u'tt3774098'}
{u'thetvdb': None, u'tvrage': 18611, u'imdb': u'tt1151434'}
{u'thetvdb': 271067, u'tvrage': None, u'imdb': u'tt2993514'}
{u'thetvdb': 80311, u'tvrage': None, u'imdb': u'tt0773264'}
{u'thetvdb': 260189, u'tvrage': 32126, u'imdb': u'tt1798695'}
{u'thetvdb': 139481, u'tvrage': 20203, u'imdb': u'tt1307083'}
{u'thetvdb': 297960, u'tvrage': 49841, u'imdb': u'tt4845734'}
{u'thetvdb': 70656, u'tvrage': None, u'imdb': u'tt0284767'}
{u'thetvdb': 80694, u'tvrage': 15758, u'imdb': u'tt0878801'}
{u'thetvdb': 282654, u'tvrage': 39954, u'imdb': u'tt3703500'}
{u'thetvdb': 272737, u'tvrage': 37535, u'imdb': u'tt3155428'}
{u'thetvdb': 76237, u'tvrage': None, u'imdb': u'tt0287196'}
{u'thetvdb': 270469, u'tvrage': 34560, u'imdb': u'tt2766052'}
{u'thetvdb': 301235, u'tvrage': None, u'imdb': u'tt0262975'}
{u'thetvdb': 126811, u'tvrage': None, u'imdb': u'tt1388381'}
{u'thetvdb': 307480, u'tvrage': None, u'imdb': u'tt0358889'}
{u'thetvdb': 83326, u'tvrage': None, u'imdb': u'tt1011591'}
{u'thetvdb': 279772, u'tvrage': None, u'imdb': u'tt3612584'}
{u'thetvdb': 305936, u'tvrage': None, u'imdb': u'tt5464192'}
{u'thetvdb': 267921, u'tvrage': None, u'imdb': u'tt4741696'}
{u'thetvdb': 95351, u'tvrage': None, u'imdb': u'tt1974439'}
{u'thetvdb': 79838, u'tvrage': 5631, u'imdb': u'tt0092325'}
{u'thetvdb': None, u'tvrage': None, u'imdb': u'tt6772826'}
{u'thetvdb': 127351, u'tvrage': 24425, u'imdb': u'tt1563069'}
{u'thetvdb': 79550, u'tvrage': 6890, u'imdb': u'tt0489598'}
{u'thetvdb': 148561, u'tvrage': 24465, u'imdb': u'tt1566154'}
{u'thetvdb': 70905, u'tvrage': 3150, u'imdb': u'tt0338592'}
{u'thetvdb': 70829, u'tvrage': None, u'imdb': u'tt0167515'}
{u'thetvdb': 262883, u'tvrage': 31271, u'imdb': u'tt2330327'}
{u'thetvdb': 84208, u'tvrage': None, u'imdb': u'tt0186747'}
{u'thetvdb': 239961, u'tvrage': 27826, u'imdb': u'tt1821877'}
{u'thetvdb': 216741, u'tvrage': None, u'imdb': u'tt1599374'}
{u'thetvdb': 270465, u'tvrage': 35836, u'imdb': u'tt2946482'}
{u'thetvdb': 268600, u'tvrage': 35103, u'imdb': u'tt2649480'}
{u'thetvdb': 82550, u'tvrage': None, u'imdb': u'tt1229945'}
{u'thetvdb': 248039, u'tvrage': 23213, u'imdb': u'tt1876612'}
|
status |
rating |
genres |
weight |
updated |
name |
language |
schedule |
url |
officialSite |
externals |
premiered |
summary |
_links |
image |
webChannel |
runtime |
type |
id |
network |
| 0 |
Ended |
{u'average': None} |
[] |
0 |
1449178946 |
Famous in 12 |
English |
{u'days': [u'Tuesday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/9024/famous-in-12 |
None |
{u'thetvdb': 279947, u'tvrage': 37045, u'imdb'... |
2014-06-03 |
<p><i><b>"Famous in 12"</b></i>, the new unscr... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
9024 |
{u'country': {u'timezone': u'America/New_York'... |
| 1 |
Ended |
{u'average': None} |
[Comedy, Family] |
14 |
1497059695 |
The Sharon Osbourne Show |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/19004/the-sharon-o... |
None |
{u'thetvdb': None, u'tvrage': 13173, u'imdb': ... |
2006-08-29 |
<p>Daily talk show hosted by Sharon Osbourne.</p> |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Talk Show |
19004 |
{u'country': {u'timezone': u'Europe/London', u... |
| 2 |
Ended |
{u'average': None} |
[Comedy] |
0 |
1503083428 |
Steve Harvey's Big Time Challenge |
English |
{u'days': [u'Sunday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/29202/steve-harvey... |
None |
{u'thetvdb': 72157, u'tvrage': None, u'imdb': ... |
2003-09-11 |
<p><b>Steve Harvey's Big Time Challenge</b>, a... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Talk Show |
29202 |
{u'country': {u'timezone': u'America/New_York'... |
| 3 |
Ended |
{u'average': None} |
[] |
0 |
1475183910 |
The Spin Crowd |
English |
{u'days': [u'Sunday'], u'time': u'22:30'} |
http://www.tvmaze.com/shows/21619/the-spin-crowd |
None |
{u'thetvdb': 218241, u'tvrage': None, u'imdb':... |
2010-08-22 |
<p>Nobody knows how to make stars shine bright... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
21619 |
{u'country': {u'timezone': u'America/New_York'... |
| 4 |
Running |
{u'average': 1} |
[] |
0 |
1495714601 |
Babushka |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/25450/babushka |
http://www.itv.com/beontv/shows/babushka |
{u'thetvdb': 327908, u'tvrage': None, u'imdb':... |
2017-05-01 |
<p><b>Babushka</b> is a brand new game show wh... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Game Show |
25450 |
{u'country': {u'timezone': u'Europe/London', u... |
| 5 |
Ended |
{u'average': None} |
[] |
0 |
1483745416 |
Chrome Underground |
English |
{u'days': [u'Tuesday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/24213/chrome-under... |
http://www.discovery.com/tv-shows/chrome-under... |
{u'thetvdb': 279810, u'tvrage': None, u'imdb':... |
2014-05-23 |
<p>Two international classic car dealers searc... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
24213 |
{u'country': {u'timezone': u'America/New_York'... |
| 6 |
Ended |
{u'average': None} |
[] |
0 |
1495602919 |
Fear Factor |
English |
{u'days': [u'Sunday'], u'time': u''} |
http://www.tvmaze.com/shows/26838/fear-factor |
None |
{u'thetvdb': 283658, u'tvrage': None, u'imdb':... |
2002-09-10 |
<p>This version has two teams of three contest... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Game Show |
26838 |
{u'country': {u'timezone': u'Europe/London', u... |
| 7 |
Ended |
{u'average': None} |
[] |
0 |
1495254081 |
Owner's Manual |
English |
{u'days': [u'Thursday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/9261/owners-manual |
None |
{u'thetvdb': 271341, u'tvrage': 33650, u'imdb'... |
2013-08-15 |
<p><b>Owner's Manual</b> will test one of the ... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
9261 |
{u'country': {u'timezone': u'America/New_York'... |
| 8 |
Ended |
{u'average': None} |
[] |
0 |
1487011574 |
The Shire |
English |
{u'days': [u'Monday'], u'time': u'21:45'} |
http://www.tvmaze.com/shows/25288/the-shire |
None |
{u'thetvdb': 260677, u'tvrage': None, u'imdb':... |
2012-07-16 |
<p>The series follows the lives and love of a ... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
25 |
Reality |
25288 |
{u'country': {u'timezone': u'Australia/Sydney'... |
| 9 |
Ended |
{u'average': None} |
[Comedy] |
0 |
1483143763 |
The Montefuscos |
English |
{u'days': [u'Thursday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/24079/the-montefuscos |
None |
{u'thetvdb': 77616, u'tvrage': None, u'imdb': ... |
1975-09-04 |
<p>The trials and tribulations of three genera... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Scripted |
24079 |
{u'country': {u'timezone': u'America/New_York'... |
| 10 |
Ended |
{u'average': None} |
[] |
0 |
1464030266 |
I Want to Be a Hilton |
English |
{u'days': [u'Tuesday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/17541/i-want-to-be... |
None |
{u'thetvdb': 74419, u'tvrage': None, u'imdb': ... |
2005-06-21 |
<p>Kathy Hilton, onetime actress and mother of... |
{u'previousepisode': {u'href': u'http://api.tv... |
None |
None |
60 |
Reality |
17541 |
{u'country': {u'timezone': u'America/New_York'... |
| 11 |
Ended |
{u'average': None} |
[] |
20 |
1478379662 |
ABC's Nightlife |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/22597/abcs-nightlife |
None |
{u'thetvdb': None, u'tvrage': None, u'imdb': u... |
1964-11-09 |
<p><b>ABC's Nightlife</b> is a late night dail... |
{u'previousepisode': {u'href': u'http://api.tv... |
None |
None |
105 |
Talk Show |
22597 |
{u'country': {u'timezone': u'America/New_York'... |
| 12 |
Running |
{u'average': None} |
[] |
0 |
1454050022 |
Untying the Knot |
English |
{u'days': [u'Monday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/6843/untying-the-knot |
http://www.bravotv.com/untying-the-knot |
{u'thetvdb': 282527, u'tvrage': 42189, u'imdb'... |
2014-06-04 |
<p>Vikki Ziegler, known as the Divorce Diva, i... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
6843 |
{u'country': {u'timezone': u'America/New_York'... |
| 13 |
Ended |
{u'average': None} |
[Action] |
0 |
1495406329 |
Wipeout Canada |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/12998/wipeout-canada |
None |
{u'thetvdb': 246631, u'tvrage': None, u'imdb':... |
2011-04-03 |
<p><b>Wipeout Canada</b> is a hilarious game s... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Game Show |
12998 |
{u'country': {u'timezone': u'Canada/Atlantic',... |
| 14 |
Ended |
{u'average': None} |
[] |
0 |
1464363967 |
Hurl! |
English |
{u'days': [u'Tuesday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/17705/hurl |
None |
{u'thetvdb': 82500, u'tvrage': None, u'imdb': ... |
2008-07-15 |
<p>Get ready to get grossed out with G4's off-... |
{u'previousepisode': {u'href': u'http://api.tv... |
None |
None |
30 |
Reality |
17705 |
{u'country': {u'timezone': u'America/New_York'... |
| 15 |
Ended |
{u'average': None} |
[] |
0 |
1457450255 |
Meet the Parents |
English |
{u'days': [u'Thursday'], u'time': u'21:30'} |
http://www.tvmaze.com/shows/13973/meet-the-par... |
http://www.channel4.com/programmes/meet-the-pa... |
{u'thetvdb': 206381, u'tvrage': 26873, u'imdb'... |
2010-11-18 |
<p><i>Meet the Parents</i> is a reality series... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
13973 |
{u'country': {u'timezone': u'Europe/London', u... |
| 16 |
Ended |
{u'average': None} |
[Drama, Action] |
0 |
1481553637 |
4th and Loud |
English |
{u'days': [u'Tuesday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/11854/4th-and-loud |
http://www.amc.com/shows/4th-and-loud |
{u'thetvdb': 284259, u'tvrage': None, u'imdb':... |
2014-08-12 |
<p><b>4th and Loud</b> will follow the LA KISS... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
11854 |
{u'country': {u'timezone': u'America/New_York'... |
| 17 |
Ended |
{u'average': None} |
[] |
0 |
1495496078 |
It's Worth What? |
English |
{u'days': [u'Tuesday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/17619/its-worth-what |
None |
{u'thetvdb': 250186, u'tvrage': None, u'imdb':... |
2011-07-19 |
<p><b>It's Worth What? </b>stars Cedric the En... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Game Show |
17619 |
{u'country': {u'timezone': u'America/New_York'... |
| 18 |
To Be Determined |
{u'average': 6.6} |
[Drama, Thriller, Adult] |
92 |
1497788418 |
The Deleted |
English |
{u'days': [], u'time': u''} |
http://www.tvmaze.com/shows/19884/the-deleted |
https://www.fullscreen.com/series/the-deleted |
{u'thetvdb': 320679, u'tvrage': None, u'imdb':... |
2016-12-04 |
<p>When escapees from a mysterious cult start ... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
{u'country': {u'timezone': u'America/New_York'... |
15 |
Scripted |
19884 |
None |
| 19 |
Ended |
{u'average': 7.3} |
[Comedy, Action, Crime] |
14 |
1500877446 |
V.I.P. |
English |
{u'days': [u'Saturday'], u'time': u''} |
http://www.tvmaze.com/shows/1885/vip |
None |
{u'thetvdb': 74181, u'tvrage': 6494, u'imdb': ... |
1998-09-26 |
<p>A campy syndicated series about Vallery Iro... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Scripted |
1885 |
{u'country': {u'timezone': u'America/New_York'... |
| 20 |
Running |
{u'average': 6} |
[Drama] |
63 |
1496679327 |
The Real Housewives of Atlanta |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/597/the-real-house... |
None |
{u'thetvdb': 84159, u'tvrage': 19672, u'imdb':... |
2008-10-07 |
<p>An up-close and personal look at life in Ho... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
597 |
{u'country': {u'timezone': u'America/New_York'... |
| 21 |
Running |
{u'average': None} |
[Comedy, Children] |
0 |
1475116665 |
Pickle and Peanut |
English |
{u'days': [u'Monday'], u'time': u'18:30'} |
http://www.tvmaze.com/shows/3019/pickle-and-pe... |
http://disneyxd.disney.com/pickle-and-peanut |
{u'thetvdb': 300105, u'tvrage': 48178, u'imdb'... |
2015-09-07 |
<p><i><b>"Pickle & Peanut"</b></i> is abou... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
{u'country': {u'timezone': u'America/New_York'... |
15 |
Animation |
3019 |
{u'country': {u'timezone': u'America/New_York'... |
| 22 |
Ended |
{u'average': None} |
[Drama, Comedy, Romance] |
0 |
1501880843 |
Buckwild |
English |
{u'days': [u'Thursday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/25036/buckwild |
http://www.mtv.com/shows/buckwild |
{u'thetvdb': 264850, u'tvrage': None, u'imdb':... |
2013-01-03 |
<p>The show follows the lives of nine young ad... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
25036 |
{u'country': {u'timezone': u'America/New_York'... |
| 23 |
Ended |
{u'average': 3} |
[] |
0 |
1486506841 |
Mystery Girls |
English |
{u'days': [u'Wednesday'], u'time': u'20:30'} |
http://www.tvmaze.com/shows/3950/mystery-girls |
http://abcfamily.go.com/shows/mystery-girls |
{u'thetvdb': 277020, u'tvrage': 35629, u'imdb'... |
2014-06-25 |
<p>Two former detective TV show starlets broug... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Scripted |
3950 |
{u'country': {u'timezone': u'America/New_York'... |
| 24 |
Running |
{u'average': None} |
[Family] |
12 |
1450883412 |
Celebrity Wife Swap |
English |
{u'days': [u'Wednesday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/1783/celebrity-wif... |
http://abc.go.com/shows/celebrity-wife-swap/ab... |
{u'thetvdb': 254524, u'tvrage': 31887, u'imdb'... |
2012-01-02 |
<p>The spouses in two celebrity families with ... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
1783 |
{u'country': {u'timezone': u'America/New_York'... |
| 25 |
Running |
{u'average': 7} |
[Comedy] |
0 |
1472855087 |
Dish Nation |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/9199/dish-nation |
http://www.reelz.com/dish-nation/ |
{u'thetvdb': 271916, u'tvrage': None, u'imdb':... |
2011-07-25 |
<p><i>Dish Nation</i> is a nightly syndicated ... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Scripted |
9199 |
{u'country': {u'timezone': u'America/New_York'... |
| 26 |
Ended |
{u'average': None} |
[Children] |
0 |
1502544202 |
Ni Hao, Kai-lan |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/13161/ni-hao-kai-lan |
None |
{u'thetvdb': 82005, u'tvrage': None, u'imdb': ... |
2008-02-07 |
<p>Ni Hao, Kai-lan , which is Mandarin for "He... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Animation |
13161 |
{u'country': {u'timezone': u'America/New_York'... |
| 27 |
Running |
{u'average': None} |
[Comedy, Family] |
0 |
1502948333 |
Scaredy Squirrel |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/20564/scaredy-squi... |
http://www.scaredysquirrel.com |
{u'thetvdb': 250472, u'tvrage': None, u'imdb':... |
2011-04-01 |
<p><b>Scaredy Squirrel </b>follows the adventu... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
10 |
Animation |
20564 |
{u'country': {u'timezone': u'Canada/Atlantic',... |
| 28 |
Running |
{u'average': None} |
[] |
76 |
1502312151 |
Big Brother After Dark |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/18240/big-brother-... |
http://poptv.com/big_brother_after_dark |
{u'thetvdb': 81491, u'tvrage': None, u'imdb': ... |
2007-07-05 |
<p><b>Big Brother After Dark</b> is the live, ... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
180 |
Reality |
18240 |
{u'country': {u'timezone': u'America/New_York'... |
| 29 |
Ended |
{u'average': 1} |
[Action, Adventure] |
0 |
1474827145 |
American Paranormal |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/19115/american-par... |
None |
{u'thetvdb': 137691, u'tvrage': None, u'imdb':... |
2010-01-24 |
<p>Whether it is the existence of aliens, the ... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
19115 |
{u'country': {u'timezone': u'America/New_York'... |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 107 |
To Be Determined |
{u'average': None} |
[] |
0 |
1495420105 |
Who's Doing the Dishes? |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/8612/whos-doing-th... |
None |
{u'thetvdb': 300384, u'tvrage': None, u'imdb':... |
2014-09-01 |
<p><b>Who's Doing the Dishes?</b> is a UK game... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Game Show |
8612 |
{u'country': {u'timezone': u'Europe/London', u... |
| 108 |
Ended |
{u'average': None} |
[] |
0 |
1474499818 |
I'm a Celebrity, Get Me Out of Here! NOW! |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/8558/im-a-celebrit... |
http://www.itv.com/imacelebrity/itv2-now |
{u'thetvdb': 264239, u'tvrage': None, u'imdb':... |
2011-11-13 |
<p><i>"I'm a Celebrity...Get Me Out of Here! N... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
8558 |
{u'country': {u'timezone': u'Europe/London', u... |
| 109 |
Ended |
{u'average': None} |
[Romance] |
0 |
1474764176 |
More to Love |
English |
{u'days': [u'Tuesday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/21467/more-to-love |
None |
{u'thetvdb': 106801, u'tvrage': None, u'imdb':... |
2009-07-28 |
<p>Follows one regular guy's search for love a... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
21467 |
{u'country': {u'timezone': u'America/New_York'... |
| 110 |
Ended |
{u'average': None} |
[] |
0 |
1467307858 |
I Want to Work for Diddy |
English |
{u'days': [u'Monday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/18829/i-want-to-wo... |
None |
{u'thetvdb': 87131, u'tvrage': None, u'imdb': ... |
2008-08-04 |
<p>Diddy. He only needs one name, but he needs... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
18829 |
{u'country': {u'timezone': u'America/New_York'... |
| 111 |
Ended |
{u'average': None} |
[] |
0 |
1490997318 |
Donald J. Trump Presents: The Ultimate Merger |
English |
{u'days': [u'Thursday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/26564/donald-j-tru... |
None |
{u'thetvdb': 173981, u'tvrage': None, u'imdb':... |
2010-06-17 |
<p>Through a series of challenges, both relati... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
26564 |
{u'country': {u'timezone': u'America/New_York'... |
| 112 |
Running |
{u'average': None} |
[] |
0 |
1477193039 |
America's Election Headquarters |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/11837/americas-ele... |
http://www.foxnews.com/on-air/americas-news-hq... |
{u'thetvdb': None, u'tvrage': None, u'imdb': u... |
2008-04-22 |
<p><b>America's Election Headquarters</b> is a... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Talk Show |
11837 |
{u'country': {u'timezone': u'America/New_York'... |
| 113 |
Running |
{u'average': None} |
[] |
45 |
1502693229 |
BBC Weekend News |
English |
{u'days': [u'Saturday', u'Sunday'], u'time': u''} |
http://www.tvmaze.com/shows/7333/bbc-weekend-news |
http://www.bbc.co.uk/programmes/b009m51q |
{u'thetvdb': 264762, u'tvrage': 31404, u'imdb'... |
1954-07-05 |
<p><b>BBC Weekend News</b> is the national new... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
None |
News |
7333 |
{u'country': {u'timezone': u'Europe/London', u... |
| 114 |
Ended |
{u'average': None} |
[Comedy, Children] |
0 |
1477293529 |
Barney & Friends |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/15482/barney-friends |
None |
{u'thetvdb': 72180, u'tvrage': None, u'imdb': ... |
1992-04-06 |
<p><b>Barney & Friends</b> is an American ... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Scripted |
15482 |
{u'country': {u'timezone': u'America/New_York'... |
| 115 |
Running |
{u'average': 7} |
[Comedy] |
89 |
1503147213 |
The Powerpuff Girls |
English |
{u'days': [u'Sunday'], u'time': u'17:30'} |
http://www.tvmaze.com/shows/6771/the-powerpuff... |
None |
{u'thetvdb': 307473, u'tvrage': None, u'imdb':... |
2016-04-04 |
<p>The city of Townsville may be a beautiful, ... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
15 |
Animation |
6771 |
{u'country': {u'timezone': u'America/New_York'... |
| 116 |
Running |
{u'average': None} |
[] |
0 |
1497251730 |
TMZ |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/24857/tmz |
http://www.tmz.com/when-its-on?adid=tmz_web_na... |
{u'thetvdb': 147701, u'tvrage': None, u'imdb':... |
2011-11-02 |
<p><b>TMZ </b>(also known simply as <i>TMZ</i>... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Talk Show |
24857 |
{u'country': {u'timezone': u'America/New_York'... |
| 117 |
Ended |
{u'average': 6} |
[] |
0 |
1476263385 |
Kendra |
English |
{u'days': [u'Sunday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/21952/kendra |
None |
{u'thetvdb': 98371, u'tvrage': None, u'imdb': ... |
2009-06-07 |
<p>Kendra Wilkinson finds herself at a crossro... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
21952 |
{u'country': {u'timezone': u'America/New_York'... |
| 118 |
Ended |
{u'average': None} |
[] |
0 |
1465065870 |
The Roseanne Show |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/12252/the-roseanne... |
None |
{u'thetvdb': 72141, u'tvrage': None, u'imdb': ... |
1998-09-14 |
<p><i><b>"The Roseanne Show"</b></i> is a synd... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Talk Show |
12252 |
{u'country': {u'timezone': u'America/New_York'... |
| 119 |
Running |
{u'average': 1} |
[Music] |
0 |
1484368515 |
The Xtra Factor Live |
English |
{u'days': [u'Saturday', u'Sunday'], u'time': u''} |
http://www.tvmaze.com/shows/3764/the-xtra-fact... |
None |
{u'thetvdb': 75567, u'tvrage': 12949, u'imdb':... |
2004-09-04 |
<p>Thousands audition. Only one can win. The s... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
3764 |
{u'country': {u'timezone': u'Europe/London', u... |
| 120 |
Ended |
{u'average': 7} |
[Comedy] |
0 |
1488031177 |
But I'm Chris Jericho! |
English |
{u'days': [u'Tuesday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/13150/but-im-chris... |
http://butimchrisjericho.com |
{u'thetvdb': 275787, u'tvrage': None, u'imdb':... |
2013-10-29 |
<p><b>But I'm Chris Jericho!</b> is an interac... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
{u'country': {u'timezone': u'America/New_York'... |
8 |
Scripted |
13150 |
{u'country': {u'timezone': u'Canada/Atlantic',... |
| 121 |
Ended |
{u'average': 6} |
[Comedy] |
0 |
1466802381 |
Party Over Here |
English |
{u'days': [u'Saturday'], u'time': u'23:00'} |
http://www.tvmaze.com/shows/12662/party-over-here |
http://www.fox.com/party-over-here |
{u'thetvdb': 308457, u'tvrage': 51439, u'imdb'... |
2016-03-12 |
<p>A new late-night half-hour sketch comedy se... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Variety |
12662 |
{u'country': {u'timezone': u'America/New_York'... |
| 122 |
Ended |
{u'average': None} |
[Action, Adventure, Horror] |
0 |
1500043650 |
Alaska Monsters |
English |
{u'days': [u'Saturday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/3124/alaska-monsters |
http://www.destinationamerica.com/tv-shows/ala... |
{u'thetvdb': 285286, u'tvrage': 44525, u'imdb'... |
2014-09-12 |
<p>Treacherous terrain and unforgiving natural... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
3124 |
{u'country': {u'timezone': u'America/New_York'... |
| 123 |
Ended |
{u'average': None} |
[Drama, Children] |
0 |
1495726406 |
Abby's Ultimate Dance Competition |
English |
{u'days': [u'Tuesday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/9420/abbys-ultimat... |
http://www.mylifetime.com/shows/abbys-ultimate... |
{u'thetvdb': 261287, u'tvrage': 32847, u'imdb'... |
2012-10-09 |
<p>Lifetime has picked-up the reality series <... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Game Show |
9420 |
{u'country': {u'timezone': u'America/New_York'... |
| 124 |
Ended |
{u'average': None} |
[Children, Mystery, Supernatural] |
0 |
1502934987 |
The Othersiders |
English |
{u'days': [u'Wednesday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/9593/the-othersiders |
None |
{u'thetvdb': 250325, u'tvrage': None, u'imdb':... |
2009-06-17 |
<p><b>The Othersiders</b> was an American para... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
9593 |
{u'country': {u'timezone': u'America/New_York'... |
| 125 |
Ended |
{u'average': None} |
[] |
0 |
1449520834 |
Canadian Idol |
English |
{u'days': [], u'time': u'20:00'} |
http://www.tvmaze.com/shows/9674/canadian-idol |
None |
{u'thetvdb': 72133, u'tvrage': None, u'imdb': ... |
2003-06-09 |
<p><i><b>"Canadian Idol"</b></i> is a Canadian... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
9674 |
{u'country': {u'timezone': u'Canada/Atlantic',... |
| 126 |
Ended |
{u'average': None} |
[] |
0 |
1474314323 |
Extreme Makeover |
English |
{u'days': [u'Thursday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/21134/extreme-make... |
None |
{u'thetvdb': 72488, u'tvrage': None, u'imdb': ... |
2002-12-11 |
<p>Three people are chosen to receive the make... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
21134 |
{u'country': {u'timezone': u'America/New_York'... |
| 127 |
Ended |
{u'average': None} |
[] |
0 |
1469556547 |
Pretty Wild |
English |
{u'days': [u'Sunday'], u'time': u'22:30'} |
http://www.tvmaze.com/shows/19522/pretty-wild |
None |
{u'thetvdb': 149371, u'tvrage': 25246, u'imdb'... |
2010-03-14 |
|
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
19522 |
{u'country': {u'timezone': u'America/New_York'... |
| 128 |
Running |
{u'average': None} |
[Comedy] |
0 |
1502570683 |
Just for Laughs: All Access |
English |
{u'days': [u'Saturday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/18044/just-for-lau... |
http://www.thecomedynetwork.ca/Shows/JustForLa... |
{u'thetvdb': 291820, u'tvrage': None, u'imdb':... |
2012-10-12 |
<p>Comedians celebrate the 30th anniversary of... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Variety |
18044 |
{u'country': {u'timezone': u'Canada/Atlantic',... |
| 129 |
Ended |
{u'average': None} |
[] |
0 |
1455387941 |
Jesse James is a Dead Man |
English |
{u'days': [u'Sunday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/12951/jesse-james-... |
None |
{u'thetvdb': 96071, u'tvrage': None, u'imdb': ... |
2009-05-31 |
<p>Jesse James takes on the role of a modern-d... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
12951 |
{u'country': {u'timezone': u'America/New_York'... |
| 130 |
Ended |
{u'average': None} |
[] |
0 |
1488221218 |
Secretly Pregnant |
English |
{u'days': [u'Thursday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/25580/secretly-pre... |
http://www.discoverylife.com/tv-shows/secretly... |
{u'thetvdb': 287516, u'tvrage': None, u'imdb':... |
2011-10-13 |
<p>The stories of women who, for various reaso... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
25580 |
{u'country': {u'timezone': u'America/New_York'... |
| 131 |
Running |
{u'average': None} |
[Family] |
13 |
1455319657 |
The Briefcase |
English |
{u'days': [], u'time': u'20:00'} |
http://www.tvmaze.com/shows/1831/the-briefcase |
None |
{u'thetvdb': 295059, u'tvrage': 48857, u'imdb'... |
2015-05-27 |
<p>The show features a social experiment eleme... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
1831 |
{u'country': {u'timezone': u'America/New_York'... |
| 132 |
Ended |
{u'average': None} |
[Comedy] |
0 |
1492370917 |
PrankStars |
English |
{u'days': [], u'time': u''} |
http://www.tvmaze.com/shows/27206/prankstars |
None |
{u'thetvdb': 250280, u'tvrage': None, u'imdb':... |
2011-07-15 |
<p>A hidden-camera series where unsuspecting t... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
27206 |
{u'country': {u'timezone': u'America/New_York'... |
| 133 |
Ended |
{u'average': None} |
[] |
0 |
1485549026 |
Cash Dome |
English |
{u'days': [u'Tuesday'], u'time': u'21:30'} |
http://www.tvmaze.com/shows/24751/cash-dome |
None |
{u'thetvdb': 272357, u'tvrage': None, u'imdb':... |
2013-08-13 |
<p>For a quarter century, <b>Cash Dome</b> Jew... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
24751 |
{u'country': {u'timezone': u'America/New_York'... |
| 134 |
Ended |
{u'average': None} |
[Comedy] |
0 |
1502593090 |
CeeLo Green's The Good Life |
English |
{u'days': [u'Monday'], u'time': u'22:30'} |
http://www.tvmaze.com/shows/25900/ceelo-greens... |
None |
{u'thetvdb': 282130, u'tvrage': None, u'imdb':... |
2014-06-23 |
<p>Follow CeeLo as he tackles not only a packe... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
25900 |
{u'country': {u'timezone': u'America/New_York'... |
| 135 |
Ended |
{u'average': None} |
[] |
0 |
1477193480 |
America's Prom Queen |
English |
{u'days': [u'Monday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/16384/americas-pro... |
None |
{u'thetvdb': None, u'tvrage': 18611, u'imdb': ... |
2008-03-17 |
<p><b>America's Prom Queen</b> is a reality TV... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
16384 |
{u'country': {u'timezone': u'America/New_York'... |
| 136 |
Ended |
{u'average': None} |
[] |
0 |
1461445299 |
Hollywood Me |
English |
{u'days': [u'Wednesday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/15972/hollywood-me |
None |
{u'thetvdb': 271067, u'tvrage': None, u'imdb':... |
2013-06-19 |
<p>Martyn Lawrence Bullard's normal clients in... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
15972 |
{u'country': {u'timezone': u'Europe/London', u... |
137 rows × 20 columns
# Create a backup occasionally, and pickle after we've pulled the data
more_losers_backup = more_losers.copy()
DO_NOT_RUN = True # Be sure to check the file name to write before enabling execution on this block
if not DO_NOT_RUN:
pickle.dump( more_losers, open( "save_more_losers_df.p", "wb" ) )
Add a column to both shows (good) and losers (bad) to classify the rows as winners or losers
# All the data pulled from api and placed in dataframes was pickled and written to disk.
# Reading it all back in and adding a column to indicate if it was a winner or loser
# then will clean up and begin the analysis.
# $ ls *.p
# save_losers_df.p save_more_losers_df.p save_shows_df.p
# read data back in from the saved file
winners = pickle.load( open( "save_shows_df.p", "rb" ) )
losers1 = pickle.load( open( "save_losers_df.p", "rb" ) )
losers2 = pickle.load( open( "save_more_losers_df.p", "rb" ) )
print " Winners:", winners.shape
print " Losers1:", losers1.shape
print " Losers2:", losers2.shape
Winners: (235, 20)
Losers1: (229, 22)
Losers2: (170, 20)
# Investigate why Losers1 has 22 columns, must have been pickled after a change.
losers1.columns
Index([u'_links', u'code', u'externals', u'genres', u'id', u'image',
u'language', u'message', u'name', u'network', u'officialSite',
u'premiered', u'rating', u'runtime', u'schedule', u'status', u'summary',
u'type', u'updated', u'url', u'webChannel', u'weight'],
dtype='object')
Index([u'status', u'rating', u'genres', u'weight', u'updated', u'name',
u'language', u'schedule', u'url', u'officialSite', u'externals',
u'premiered', u'summary', u'_links', u'image', u'webChannel',
u'runtime', u'type', u'id', u'network'],
dtype='object')
Index([u'status', u'rating', u'genres', u'weight', u'updated', u'name',
u'language', u'schedule', u'url', u'officialSite', u'externals',
u'premiered', u'summary', u'_links', u'image', u'webChannel',
u'runtime', u'type', u'id', u'network'],
dtype='object')
# Correct the issue by copying correct columns from losers1 into new_losers1
cols = losers2.columns
new_losers1 = losers1[cols]
# check that all three dataframes have same data in same order
winners.head(2)
|
status |
rating |
genres |
weight |
updated |
name |
language |
schedule |
url |
officialSite |
externals |
premiered |
summary |
_links |
image |
webChannel |
runtime |
type |
id |
network |
| 0 |
Ended |
{u'average': 9.4} |
[Nature] |
87 |
1490631396 |
Planet Earth II |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/22036/planet-earth-ii |
http://www.bbc.co.uk/programmes/p02544td |
{u'thetvdb': 318408, u'tvrage': None, u'imdb':... |
2016-11-06 |
<p>David Attenborough presents a documentary s... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Documentary |
22036 |
{u'country': {u'timezone': u'Europe/London', u... |
| 1 |
Ended |
{u'average': 9.4} |
[Drama, Action, War, History] |
86 |
1492651730 |
Band of Brothers |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/465/band-of-brothers |
http://www.hbo.com/band-of-brothers |
{u'thetvdb': 74205, u'tvrage': 2708, u'imdb': ... |
2001-09-09 |
<p>Drawn from interviews with survivors of Eas... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Scripted |
465 |
{u'country': {u'timezone': u'America/New_York'... |
|
status |
rating |
genres |
weight |
updated |
name |
language |
schedule |
url |
officialSite |
externals |
premiered |
summary |
_links |
image |
webChannel |
runtime |
type |
id |
network |
| 0 |
Running |
{u'average': None} |
[] |
63 |
1463447317 |
The Bill Cunningham Show |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/6068/the-bill-cunn... |
http://www.thebillcunninghamshow.com/ |
{u'thetvdb': 283995, u'tvrage': 40425, u'imdb'... |
2011-09-19 |
<p><i><b>"The Bill Cunningham Show"</b>,</i> T... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Talk Show |
6068 |
{u'country': {u'timezone': u'America/New_York'... |
| 1 |
To Be Determined |
{u'average': None} |
[Comedy, Music] |
0 |
1477139892 |
Six Degrees of Everything |
English |
{u'days': [u'Tuesday'], u'time': u'23:00'} |
http://www.tvmaze.com/shows/2821/six-degrees-o... |
http://www.trutv.com/shows/six-degrees-of-ever... |
{u'thetvdb': 299234, u'tvrage': 50418, u'imdb'... |
2015-08-18 |
<p><b>Six Degrees of Everything</b> is a fast-... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Variety |
2821 |
{u'country': {u'timezone': u'America/New_York'... |
|
status |
rating |
genres |
weight |
updated |
name |
language |
schedule |
url |
officialSite |
externals |
premiered |
summary |
_links |
image |
webChannel |
runtime |
type |
id |
network |
| 0 |
Ended |
{u'average': None} |
[] |
0 |
1449178946 |
Famous in 12 |
English |
{u'days': [u'Tuesday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/9024/famous-in-12 |
None |
{u'thetvdb': 279947, u'tvrage': 37045, u'imdb'... |
2014-06-03 |
<p><i><b>"Famous in 12"</b></i>, the new unscr... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Reality |
9024 |
{u'country': {u'timezone': u'America/New_York'... |
| 1 |
Ended |
{u'average': None} |
[Comedy, Family] |
14 |
1497059695 |
The Sharon Osbourne Show |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/19004/the-sharon-o... |
None |
{u'thetvdb': None, u'tvrage': 13173, u'imdb': ... |
2006-08-29 |
<p>Daily talk show hosted by Sharon Osbourne.</p> |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Talk Show |
19004 |
{u'country': {u'timezone': u'Europe/London', u... |
# Add a column to classify the shows as winners or losers (not winners)
winners['winner'] = 1
new_losers1['winner'] = 0
losers2['winner'] = 0
/Users/erhepp/anaconda/lib/python2.7/site-packages/ipykernel_launcher.py:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
This is separate from the ipykernel package so we can avoid doing imports until
Merge into one dataframe called shows
# now concatenate the loser data to the winner data, the result is the dataframe shows
shows = pd.DataFrame()
shows = winners.copy()
shows = shows.append(new_losers1, ignore_index=True)
shows = shows.append(losers2, ignore_index=True)
shows.shape
|
status |
rating |
genres |
weight |
updated |
name |
language |
schedule |
url |
officialSite |
... |
premiered |
summary |
_links |
image |
webChannel |
runtime |
type |
id |
network |
winner |
| 0 |
Ended |
{u'average': 9.4} |
[Nature] |
87 |
1490631396 |
Planet Earth II |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/22036/planet-earth-ii |
http://www.bbc.co.uk/programmes/p02544td |
... |
2016-11-06 |
<p>David Attenborough presents a documentary s... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Documentary |
22036 |
{u'country': {u'timezone': u'Europe/London', u... |
1 |
| 1 |
Ended |
{u'average': 9.4} |
[Drama, Action, War, History] |
86 |
1492651730 |
Band of Brothers |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/465/band-of-brothers |
http://www.hbo.com/band-of-brothers |
... |
2001-09-09 |
<p>Drawn from interviews with survivors of Eas... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Scripted |
465 |
{u'country': {u'timezone': u'America/New_York'... |
1 |
| 2 |
Ended |
{u'average': 9.2} |
[Nature] |
82 |
1502854135 |
Planet Earth |
English |
{u'days': [u'Sunday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/768/planet-earth |
http://www.bbc.co.uk/programmes/b006mywy |
... |
2006-03-05 |
<p>David Attenborough celebrates the amazing v... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Documentary |
768 |
{u'country': {u'timezone': u'Europe/London', u... |
1 |
| 3 |
Running |
{u'average': 9.3} |
[Drama, Adventure, Fantasy] |
100 |
1502955537 |
Game of Thrones |
English |
{u'days': [u'Sunday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/82/game-of-thrones |
http://www.hbo.com/game-of-thrones |
... |
2011-04-17 |
<p>Based on the bestselling book series <i>A S... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Scripted |
82 |
{u'country': {u'timezone': u'America/New_York'... |
1 |
| 4 |
Ended |
{u'average': 9.3} |
[Drama, Crime, Thriller] |
97 |
1502331382 |
Breaking Bad |
English |
{u'days': [u'Sunday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/169/breaking-bad |
http://www.amc.com/shows/breaking-bad |
... |
2008-01-20 |
<p><b>Breaking Bad</b> follows protagonist Wal... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Scripted |
169 |
{u'country': {u'timezone': u'America/New_York'... |
1 |
5 rows × 21 columns
# Check id column for any duplicates. There will be some from the losers for two reasons:
# During first pull, the API limitions were not known, so some were returned with message,
# "Too Many Requests" rather tahn data, these need to be removed
# Some did not contain their own imdb number in the data, so when the list of imdb #s to recheck was generated,
# these had to be included in the 2nd attempt as they could not be identified as being in the first pull.
shows = shows[shows['name'] != 'Too Many Requests']
print shows.shape
print "Duplicate show IDs", shows.duplicated('id').sum()
# Display the duplicates to visually examine before dropping
# shows[shows.isin(shows[shows.duplicated()])].sort("ID")
shows[shows.duplicated('id')]
(498, 21)
Duplicate show IDs 6
|
status |
rating |
genres |
weight |
updated |
name |
language |
schedule |
url |
officialSite |
... |
premiered |
summary |
_links |
image |
webChannel |
runtime |
type |
id |
network |
winner |
| 601 |
Ended |
{u'average': None} |
[] |
0 |
1477683583 |
Tyler Perry's House of Payne |
English |
{u'days': [u'Friday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/14013/tyler-perrys... |
None |
... |
2007-06-06 |
<p><b>Tyler Perry's House of Payne</b> is a co... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Scripted |
14013 |
{u'country': {u'timezone': u'America/New_York'... |
0 |
| 602 |
Ended |
{u'average': 3.3} |
[Comedy] |
4 |
1502774582 |
The Inbetweeners |
English |
{u'days': [u'Monday'], u'time': u'22:30'} |
http://www.tvmaze.com/shows/1138/the-inbetweeners |
None |
... |
2012-08-20 |
<p><b>The Inbetweeners</b> takes a comedic loo... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Scripted |
1138 |
{u'country': {u'timezone': u'America/New_York'... |
0 |
| 603 |
Ended |
{u'average': 6} |
[Family] |
0 |
1497646938 |
19 Kids and Counting |
English |
{u'days': [u'Tuesday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/969/19-kids-and-co... |
http://www.tlc.com/tv-shows/19-kids-and-counting/ |
... |
2008-09-29 |
<p><b>19 Kids and Counting</b> follows Michell... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Reality |
969 |
{u'country': {u'timezone': u'America/New_York'... |
0 |
| 604 |
Ended |
{u'average': 9} |
[Comedy, Food, Family] |
0 |
1463627692 |
Talia in the Kitchen |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/2369/talia-in-the-... |
http://www.nick.com/talia-in-the-kitchen/ |
... |
2015-07-06 |
<p>When 14-year-old Talia visits her grandmoth... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
30 |
Scripted |
2369 |
{u'country': {u'timezone': u'America/New_York'... |
0 |
| 605 |
Running |
{u'average': 3.8} |
[] |
48 |
1497310190 |
The Factor |
English |
{u'days': [u'Monday', u'Tuesday', u'Wednesday'... |
http://www.tvmaze.com/shows/9066/the-factor |
http://www.foxnews.com/shows/the-oreilly-facto... |
... |
1996-10-07 |
<p><b>The Factor</b>, originally titled <i>The... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
News |
9066 |
{u'country': {u'timezone': u'America/New_York'... |
0 |
| 606 |
Ended |
{u'average': None} |
[Drama, Comedy, Music] |
0 |
1462214107 |
Viva Laughlin |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/6924/viva-laughlin |
None |
... |
2007-10-18 |
<p>A remake of the British series <i>Blackpool... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Scripted |
6924 |
{u'country': {u'timezone': u'America/New_York'... |
0 |
6 rows × 21 columns
# validate that these are really dups by looking at both rows with the duplicate id
shows[shows['id'] == 6924]
|
status |
rating |
genres |
weight |
updated |
name |
language |
schedule |
url |
officialSite |
... |
premiered |
summary |
_links |
image |
webChannel |
runtime |
type |
id |
network |
winner |
| 462 |
Ended |
{u'average': None} |
[Drama, Comedy, Music] |
0 |
1462214107 |
Viva Laughlin |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/6924/viva-laughlin |
None |
... |
2007-10-18 |
<p>A remake of the British series <i>Blackpool... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Scripted |
6924 |
{u'country': {u'timezone': u'America/New_York'... |
0 |
| 606 |
Ended |
{u'average': None} |
[Drama, Comedy, Music] |
0 |
1462214107 |
Viva Laughlin |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/6924/viva-laughlin |
None |
... |
2007-10-18 |
<p>A remake of the British series <i>Blackpool... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
Scripted |
6924 |
{u'country': {u'timezone': u'America/New_York'... |
0 |
2 rows × 21 columns
# All 6 of these check out as true duplicates, so remove the 2nd instance of each
shows = shows.drop_duplicates(subset='id')
# make a copy, so there's a backup without having to re-pull shows info from api or from pickle and recombine
df_shows = shows.copy()
# Subdivide the columns so we can fit sections of the dataframe in notebook windows to see what we have
first_cols = df_shows.columns[1:10]
second_cols = df_shows.columns[10:17]
third_cols = df_shows.columns[17:]
df_shows[first_cols].head()
|
rating |
genres |
weight |
updated |
name |
language |
schedule |
url |
officialSite |
| 0 |
{u'average': 9.4} |
[Nature] |
87 |
1490631396 |
Planet Earth II |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/22036/planet-earth-ii |
http://www.bbc.co.uk/programmes/p02544td |
| 1 |
{u'average': 9.4} |
[Drama, Action, War, History] |
86 |
1492651730 |
Band of Brothers |
English |
{u'days': [u'Sunday'], u'time': u'20:00'} |
http://www.tvmaze.com/shows/465/band-of-brothers |
http://www.hbo.com/band-of-brothers |
| 2 |
{u'average': 9.2} |
[Nature] |
82 |
1502854135 |
Planet Earth |
English |
{u'days': [u'Sunday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/768/planet-earth |
http://www.bbc.co.uk/programmes/b006mywy |
| 3 |
{u'average': 9.3} |
[Drama, Adventure, Fantasy] |
100 |
1502955537 |
Game of Thrones |
English |
{u'days': [u'Sunday'], u'time': u'21:00'} |
http://www.tvmaze.com/shows/82/game-of-thrones |
http://www.hbo.com/game-of-thrones |
| 4 |
{u'average': 9.3} |
[Drama, Crime, Thriller] |
97 |
1502331382 |
Breaking Bad |
English |
{u'days': [u'Sunday'], u'time': u'22:00'} |
http://www.tvmaze.com/shows/169/breaking-bad |
http://www.amc.com/shows/breaking-bad |
df_shows[second_cols].head()
|
externals |
premiered |
summary |
_links |
image |
webChannel |
runtime |
| 0 |
{u'thetvdb': 318408, u'tvrage': None, u'imdb':... |
2016-11-06 |
<p>David Attenborough presents a documentary s... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
| 1 |
{u'thetvdb': 74205, u'tvrage': 2708, u'imdb': ... |
2001-09-09 |
<p>Drawn from interviews with survivors of Eas... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
| 2 |
{u'thetvdb': 79257, u'tvrage': 8077, u'imdb': ... |
2006-03-05 |
<p>David Attenborough celebrates the amazing v... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
| 3 |
{u'thetvdb': 121361, u'tvrage': 24493, u'imdb'... |
2011-04-17 |
<p>Based on the bestselling book series <i>A S... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
| 4 |
{u'thetvdb': 81189, u'tvrage': 18164, u'imdb':... |
2008-01-20 |
<p><b>Breaking Bad</b> follows protagonist Wal... |
{u'previousepisode': {u'href': u'http://api.tv... |
{u'medium': u'http://static.tvmaze.com/uploads... |
None |
60 |
df_shows[third_cols].head()
|
type |
id |
network |
winner |
| 0 |
Documentary |
22036 |
{u'country': {u'timezone': u'Europe/London', u... |
1 |
| 1 |
Scripted |
465 |
{u'country': {u'timezone': u'America/New_York'... |
1 |
| 2 |
Documentary |
768 |
{u'country': {u'timezone': u'Europe/London', u... |
1 |
| 3 |
Scripted |
82 |
{u'country': {u'timezone': u'America/New_York'... |
1 |
| 4 |
Scripted |
169 |
{u'country': {u'timezone': u'America/New_York'... |
1 |
Cleanup and Organization of the DataFrame
# Cleanup and Organization
# The genres column is generally a list of strings, but is missing some values, and has empty lists for others.
# !. Change all NaN to []
# 2. Convert all to strings
# 3. Use Count Vectorizer to make new columns for each genre
# 4. Remove existing genres column
df_shows['genres'] = df_shows['genres'].fillna(0).map(lambda x: [] if x == 0 else x)
df_shows['genres'] = df_shows['genres'].map(lambda x: ','.join(x))
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(
binary=True,
tokenizer=(lambda x: x.split(','))
)
cvfit = cv.fit_transform(df_shows['genres']).todense()
genre_cols = pd.DataFrame(cvfit, columns=cv.get_feature_names())
genre_cols.rename(columns={'' : 'unknown'}, inplace=True)
genre_cols.columns
Index([ u'unknown', u'action', u'adult',
u'adventure', u'anime', u'children',
u'comedy', u'crime', u'drama',
u'espionage', u'family', u'fantasy',
u'food', u'history', u'horror',
u'legal', u'medical', u'music',
u'mystery', u'nature', u'romance',
u'science-fiction', u'sports', u'supernatural',
u'thriller', u'travel', u'war',
u'western'],
dtype='object')
new_genre_columns = []
for item in genre_cols:
new_genre_columns.append('gn_' + item)
genre_cols.columns = new_genre_columns
genre_cols.head()
|
gn_unknown |
gn_action |
gn_adult |
gn_adventure |
gn_anime |
gn_children |
gn_comedy |
gn_crime |
gn_drama |
gn_espionage |
... |
gn_mystery |
gn_nature |
gn_romance |
gn_science-fiction |
gn_sports |
gn_supernatural |
gn_thriller |
gn_travel |
gn_war |
gn_western |
| 0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
| 2 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 3 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 4 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
5 rows × 28 columns
# Add the new genre columns to the df_shows dataframe
df_shows = pd.concat([df_shows, genre_cols], axis=1, join_axes=[df_shows.index])
df_shows = df_shows.drop('genres', 1)
# Genre information is missing for 69 loser shows and 13 winner shows
df_shows[df_shows['gn_unknown'] ==1][['gn_unknown', 'winner']].groupby(['winner']).count()
|
gn_unknown |
| winner |
|
| 0 |
69 |
| 1 |
13 |
Index([ u'status', u'rating', u'weight',
u'updated', u'name', u'language',
u'schedule', u'url', u'officialSite',
u'externals', u'premiered', u'summary',
u'_links', u'image', u'webChannel',
u'runtime', u'type', u'id',
u'network', u'winner', u'gn_unknown',
u'gn_action', u'gn_adult', u'gn_adventure',
u'gn_anime', u'gn_children', u'gn_comedy',
u'gn_crime', u'gn_drama', u'gn_espionage',
u'gn_family', u'gn_fantasy', u'gn_food',
u'gn_history', u'gn_horror', u'gn_legal',
u'gn_medical', u'gn_music', u'gn_mystery',
u'gn_nature', u'gn_romance', u'gn_science-fiction',
u'gn_sports', u'gn_supernatural', u'gn_thriller',
u'gn_travel', u'gn_war', u'gn_western'],
dtype='object')
# Convert the rating to a number
# sometimes the rating column is NaN, and sometimes the value for 'average' in the dictionary is Nan
# so the NaNs must be handled twice, once for each case
# This code first fills the missing dictionarys with -1 (value chosen to signify no rating)
# It then sets the column to the average value in the rating dictionary, and if that is NaN converts to -1
df_shows['rating'] = df_shows['rating'].fillna(-1).map(lambda x: -1 if x == -1 else x['average']).fillna(-1)
# Rating information is missing for 192 loser shows and 6 winner shows
df_shows[df_shows['rating'] == -1][['rating', 'winner']].groupby(['winner']).count()
# Unpack 'schedule' into days treating NaN in a similar way,
df_shows['sched_day'] = df_shows['schedule'].fillna(0).map(lambda x: [] if x == 0 else x)
df_shows['sched_day'] = df_shows['sched_day'].map(lambda x: x if x == [] else x['days'])
df_shows['sched_day'] = df_shows['sched_day'].map(lambda x: ','.join(x))
cv = CountVectorizer(
binary=True,
tokenizer=(lambda x: x.split(','))
)
cvfit = cv.fit_transform(df_shows['sched_day']).todense()
day_cols = pd.DataFrame(cvfit, columns=cv.get_feature_names())
day_cols.rename(columns={'' : 'unknown'}, inplace=True)
day_cols.columns
Index([ u'unknown', u'friday', u'monday', u'saturday', u'sunday',
u'thursday', u'tuesday', u'wednesday'],
dtype='object')
new_day_columns = []
for item in day_cols:
new_day_columns.append('sched_' + item)
day_cols.columns = new_day_columns
day_cols.head()
|
sched_unknown |
sched_friday |
sched_monday |
sched_saturday |
sched_sunday |
sched_thursday |
sched_tuesday |
sched_wednesday |
| 0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
| 1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
| 2 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
| 3 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
| 4 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
# Add the new genre columns to the df_shows dataframe
df_shows = pd.concat([df_shows, day_cols], axis=1, join_axes=[df_shows.index])
df_shows = df_shows.drop('sched_day', 1)
# Scheduled Day information is missing for 15 loser shows and 45 winner shows
df_shows[df_shows['sched_unknown'] ==1][['sched_unknown', 'winner']].groupby(['winner']).count()
|
sched_unknown |
| winner |
|
| 0 |
15 |
| 1 |
45 |
# Unpack 'schedule' into times treating NaN in a similar way.
# Samples with a valid show time will be HH:MM and missing values will be :
df_shows['sched_time'] = df_shows['schedule'].fillna(':').map(lambda x: x if x == ':' else x['time'])
df_shows['sched_time'] = df_shows['sched_time'].map(lambda x: ':' if x == '' else x)
# Scheduled Time information is missing for 35 loser shows and 61 winner shows
print len(df_shows[df_shows['sched_time'] == ':'])
df_shows[df_shows['sched_time'] == ':'][['sched_time', 'winner']].groupby(['winner']).count()
|
sched_time |
| winner |
|
| 0 |
35 |
| 1 |
61 |
# Sched time is in HH:MM format as a string. I will leave this as string, and count vectorize it
print type(df_shows.loc[0,'sched_time'])
cv = CountVectorizer(
binary=True,
tokenizer=(lambda x: x.split(','))
)
cvfit = cv.fit_transform(df_shows['sched_time']).todense()
time_cols = pd.DataFrame(cvfit, columns=cv.get_feature_names())
time_cols.rename(columns={':' : 'unknown'}, inplace=True)
time_cols.columns
<type 'unicode'>
Index([ u'00:00', u'00:30', u'00:50', u'00:55', u'01:00', u'01:05',
u'01:30', u'01:35', u'02:00', u'02:05', u'08:00', u'10:00',
u'11:00', u'12:00', u'13:00', u'13:30', u'14:00', u'14:30',
u'15:00', u'15:15', u'16:00', u'16:30', u'17:00', u'17:15',
u'17:30', u'18:00', u'18:30', u'19:00', u'19:30', u'19:45',
u'20:00', u'20:15', u'20:30', u'20:40', u'20:45', u'20:55',
u'21:00', u'21:10', u'21:15', u'21:30', u'21:45', u'22:00',
u'22:10', u'22:30', u'22:35', u'23:00', u'23:02', u'23:15',
u'23:30', u'unknown'],
dtype='object')
new_time_columns = []
for item in time_cols:
new_time_columns.append('sched_time_' + item)
time_cols.columns = new_time_columns
time_cols.head()
|
sched_time_00:00 |
sched_time_00:30 |
sched_time_00:50 |
sched_time_00:55 |
sched_time_01:00 |
sched_time_01:05 |
sched_time_01:30 |
sched_time_01:35 |
sched_time_02:00 |
sched_time_02:05 |
... |
sched_time_21:45 |
sched_time_22:00 |
sched_time_22:10 |
sched_time_22:30 |
sched_time_22:35 |
sched_time_23:00 |
sched_time_23:02 |
sched_time_23:15 |
sched_time_23:30 |
sched_time_unknown |
| 0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 2 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 3 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 4 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
5 rows × 50 columns
# Add the new genre columns to the df_shows dataframe
df_shows = pd.concat([df_shows, time_cols], axis=1, join_axes=[df_shows.index])
df_shows = df_shows.drop('schedule', 1)
df_shows = df_shows.drop('sched_time', 1)
Index([ u'status', u'rating', u'weight',
u'updated', u'name', u'language',
u'url', u'officialSite', u'externals',
u'premiered',
...
u'sched_time_21:45', u'sched_time_22:00', u'sched_time_22:10',
u'sched_time_22:30', u'sched_time_22:35', u'sched_time_23:00',
u'sched_time_23:02', u'sched_time_23:15', u'sched_time_23:30',
u'sched_time_unknown'],
dtype='object', length=105)
# Print out a network dictionary to learn how to unpack the structure
df_shows.loc[0,'network']
{u'country': {u'code': u'GB',
u'name': u'United Kingdom',
u'timezone': u'Europe/London'},
u'id': 12,
u'name': u'BBC One'}
# 25 shows have no network info, might need to drop these, but dummied for now
df_shows['network'].isnull().sum()
# Unpack 'network' into country code, country name, timezone, treating NaN in a similar way,
df_shows['country_code'] = df_shows['network'].fillna('').map(lambda x: x if x == '' else x['country'])
df_shows['country_code'] = df_shows['country_code'].map(lambda x: x if x == '' else x['code'])
df_shows['country_name'] = df_shows['network'].fillna('').map(lambda x: x if x == '' else x['country'])
df_shows['country_name'] = df_shows['country_name'].map(lambda x: x if x == '' else x['name'])
df_shows['country_tz'] = df_shows['network'].fillna('').map(lambda x: x if x == '' else x['country'])
df_shows['country_tz'] = df_shows['country_tz'].map(lambda x: x if x == '' else x['timezone'])
df_shows['network_id'] = df_shows['network'].fillna('').map(lambda x: x if x == '' else x['id'])
df_shows['network_name'] = df_shows['network'].fillna('').map(lambda x: x if x == '' else x['name'])
df_shows = df_shows.drop(['network'], 1)
# Country and network information is missing for 4 loser shows and 21 winner shows
df_shows[df_shows['country_code'] == ''] [['country_code', 'winner']].groupby(['winner']).count()
|
country_code |
| winner |
|
| 0 |
4 |
| 1 |
21 |
df_shows[['country_code', 'country_name', 'country_tz', 'network_id', 'network_name']].head()
|
country_code |
country_name |
country_tz |
network_id |
network_name |
| 0 |
GB |
United Kingdom |
Europe/London |
12 |
BBC One |
| 1 |
US |
United States |
America/New_York |
8 |
HBO |
| 2 |
GB |
United Kingdom |
Europe/London |
12 |
BBC One |
| 3 |
US |
United States |
America/New_York |
8 |
HBO |
| 4 |
US |
United States |
America/New_York |
20 |
AMC |
df_shows[['updated', 'premiered']].head()
|
updated |
premiered |
| 0 |
1490631396 |
2016-11-06 |
| 1 |
1492651730 |
2001-09-09 |
| 2 |
1502854135 |
2006-03-05 |
| 3 |
1502955537 |
2011-04-17 |
| 4 |
1502331382 |
2008-01-20 |
# Updated date is complete, premiered date is missing 6 values
print df_shows['updated'].isnull().sum()
print df_shows['premiered'].isnull().sum()
# Must represent updated as a real date time object, currently is seconds from epoch (1970)
# Convert string to int, then int to datetime
import datetime
print type(df_shows.loc[0,'updated'])
df_shows['updated'] = df_shows['updated'].fillna(0).apply(lambda x: x if x == 0 else datetime.datetime.fromtimestamp(x))
# Turn premiered into real date time object, currently this is a string, need to convert to date
print type(df_shows.loc[0,'premiered'])
df_shows['premiered'] = df_shows['premiered'].fillna(0).apply(lambda x: x if x == 0 else datetime.datetime.strptime(x, '%Y-%m-%d'))
df_shows[['updated', 'premiered']].head()
|
updated |
premiered |
| 0 |
2017-03-27 12:16:36 |
2016-11-06 00:00:00 |
| 1 |
2017-04-19 21:28:50 |
2001-09-09 00:00:00 |
| 2 |
2017-08-15 23:28:55 |
2006-03-05 00:00:00 |
| 3 |
2017-08-17 03:38:57 |
2011-04-17 00:00:00 |
| 4 |
2017-08-09 22:16:22 |
2008-01-20 00:00:00 |
# Updated date is complete, premiered date is missing 6 values, all from loser shows
df_shows[df_shows['premiered'] == 0] [['premiered', 'winner']].groupby(['winner']).count()
# Drop columns not useful for analysis
# webChannel has no or insufficient useful information, can drop
print "webChannel null count:", df_shows['webChannel'].isnull().sum()
# url, officialSite, externals, _links, image, webChannel
df_shows = df_shows.drop(['url', 'officialSite', 'externals', '_links', 'image', 'webChannel', ], 1)
webChannel null count: 464
# Looks like runtime is already an integer number of minutes
# runtime is missing 9 values, 5 winners and 4 losers
print type(df_shows.loc[0,'runtime'])
print df_shows['runtime'].isnull().sum(), " null values"
# df_shows['runtime'].value_counts()
<type 'int'>
9 null values
df_shows[df_shows['runtime'].isnull()][['runtime', 'winner']]
|
runtime |
winner |
| 17 |
None |
1 |
| 65 |
None |
1 |
| 137 |
None |
1 |
| 144 |
None |
1 |
| 198 |
None |
1 |
| 544 |
None |
0 |
| 556 |
None |
0 |
| 577 |
None |
0 |
| 609 |
None |
0 |
# Contains html tags, otherwise a string, html tags will be removed in text processing steps during analysis
print df_shows.loc[0,'summary']
print df_shows['summary'].isnull().sum(), " null values"
<p>David Attenborough presents a documentary series exploring how animals meet the challenges of surviving in the most iconic habitats on earth.</p>
1 null values
df_shows[df_shows['summary'].isnull()]
|
status |
rating |
weight |
updated |
name |
language |
premiered |
summary |
runtime |
type |
... |
sched_time_23:00 |
sched_time_23:02 |
sched_time_23:15 |
sched_time_23:30 |
sched_time_unknown |
country_code |
country_name |
country_tz |
network_id |
network_name |
| 570 |
Ended |
-1.0 |
75 |
2017-04-18 17:55:28 |
Chop Socky Chooks |
English |
2008-03-07 00:00:00 |
None |
11 |
Animation |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
11 |
Cartoon Network |
1 rows × 104 columns
# This one with the missing summary, Chop Socky Chooks, is missing other information also, and will be dropped.
# Too bad, looks like a truly dreadful one that would be good for the very bottom of the losers list.
df_shows = df_shows[df_shows['summary'].notnull()]
df_shows.shape
# Use textacy to clean the html tags, punctuation, etc. from the summary text
from textacy.preprocess import preprocess_text
df_shows['summary'] = df_shows['summary'].map(lambda x: preprocess_text(x, fix_unicode=True, lowercase=True, \
transliterate=False, no_contractions = True,
no_urls=True, no_emails=True, no_phone_numbers=True, no_currency_symbols=True,
no_punct=True, no_accents=True))
print df_shows.loc[1,'summary']
print
print df_shows.loc[2,'summary']
<p>drawn from interviews with survivors of easy company as well as their journals and letters <b>band of brothers<b> chronicles the experiences of these men from paratrooper training in georgia through the end of the war as an elite rifle company parachuting into normandy early on dday morning participants in the battle of the bulge and witness to the horrors of war the men of easy knew extraordinary bravery and extraordinary fear and became the stuff of legend based on stephen e ambroses acclaimed book of the same name<p>
<p>david attenborough celebrates the amazing variety of the natural world in this epic documentary series filmed over four years across 64 different countries<p>
# Looks like all the summaries have html paragraph <p> and break <b> tags, and textacy hasn't removed them.
# These lambda function knock them out
import string
df_shows['summary'] = df_shows['summary'].map(lambda x: x.replace('<p>',''))
df_shows['summary'] = df_shows['summary'].map(lambda x: x.replace('<b>',''))
# This looks better for analysis
print df_shows.loc[1,'summary']
drawn from interviews with survivors of easy company as well as their journals and letters band of brothers chronicles the experiences of these men from paratrooper training in georgia through the end of the war as an elite rifle company parachuting into normandy early on dday morning participants in the battle of the bulge and witness to the horrors of war the men of easy knew extraordinary bravery and extraordinary fear and became the stuff of legend based on stephen e ambroses acclaimed book of the same name
df_shows[df_shows.isnull().any(axis=1)]
|
status |
rating |
weight |
updated |
name |
language |
premiered |
summary |
runtime |
type |
... |
sched_time_23:00 |
sched_time_23:02 |
sched_time_23:15 |
sched_time_23:30 |
sched_time_unknown |
country_code |
country_name |
country_tz |
network_id |
network_name |
| 17 |
Ended |
9.0 |
0 |
1455913373 |
The Decalogue |
Polish |
1989-12-10 00:00:00 |
<p>Ten television drama films, each one based ... |
None |
Variety |
... |
0.0 |
0.0 |
0.0 |
0.0 |
1.0 |
PL |
Poland |
Europe/Warsaw |
336 |
TVP1 |
| 65 |
Ended |
9.0 |
85 |
1501781828 |
Sherlock Holmes |
English |
1984-04-24 00:00:00 |
<p><b>Sherlock Holmes</b> is one of the world'... |
None |
Scripted |
... |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
GB |
United Kingdom |
Europe/London |
35 |
ITV |
| 137 |
Running |
8.7 |
98 |
1489944935 |
Taboo |
English |
2017-01-07 00:00:00 |
<p>1814: James Keziah Delaney returns to Londo... |
None |
Scripted |
... |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
GB |
United Kingdom |
Europe/London |
12 |
BBC One |
| 144 |
Ended |
8.6 |
42 |
1494693177 |
The New Batman Adventures |
English |
1997-09-13 00:00:00 |
<p>The New Batman Adventures comes from the cr... |
None |
Animation |
... |
0.0 |
0.0 |
0.0 |
0.0 |
1.0 |
US |
United States |
America/New_York |
71 |
The WB |
| 198 |
Ended |
9.0 |
0 |
1491564027 |
The Larry Sanders Show |
English |
1992-08-15 00:00:00 |
<p>Comic Garry Shandling draws upon his own ta... |
None |
Scripted |
... |
0.0 |
0.0 |
0.0 |
0.0 |
1.0 |
US |
United States |
America/New_York |
8 |
HBO |
| 492 |
Running |
-1.0 |
76 |
1502312151 |
Big Brother After Dark |
English |
2007-07-05 00:00:00 |
<p><b>Big Brother After Dark</b> is the live, ... |
180 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
88 |
Pop |
| 493 |
Ended |
1.0 |
0 |
1474827145 |
American Paranormal |
English |
2010-01-24 00:00:00 |
<p>Whether it is the existence of aliens, the ... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
42 |
National Geographic Channel |
| 494 |
Ended |
-1.0 |
11 |
1469108505 |
Homeboys in Outer Space |
English |
1996-08-27 00:00:00 |
<p>The plot centers around two astronauts, Tyb... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
70 |
UPN |
| 495 |
Ended |
-1.0 |
0 |
1485097253 |
Gainesville: Friends Are Family |
English |
2015-08-20 00:00:00 |
<p><i><b>"Gainesville: Friends Are Family"</b>... |
30 |
Documentary |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
173 |
CMT |
| 496 |
Ended |
-1.0 |
0 |
1449234102 |
The Show with Vinny |
English |
2013-05-01 00:00:00 |
<p>Vinny Guadagnino invites musicians, TV star... |
30 |
Talk Show |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
22 |
MTV |
| 497 |
Ended |
-1.0 |
0 |
1457985576 |
Gormiti Nature Unleashed |
French |
2013-04-01 00:00:00 |
<p>Gormiti Nature Unleashed is an Italian CGI ... |
25 |
Animation |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
FR |
France |
Europe/Paris |
1050 |
Canal J |
| 498 |
Ended |
-1.0 |
23 |
1483294279 |
Denise Richards: It's Complicated |
English |
2008-05-26 00:00:00 |
<p><b>Denise Richards: It's Complicated</b> is... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
43 |
E! |
| 499 |
Ended |
-1.0 |
0 |
1482875019 |
Stanley |
English |
1956-09-24 00:00:00 |
<p><b>Stanley</b> revolved around the adventur... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
1 |
NBC |
| 500 |
Ended |
1.0 |
0 |
1468782928 |
Uncovering Aliens |
English |
2013-12-15 00:00:00 |
<p>Across America, there are more UFO sighting... |
60 |
Documentary |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
92 |
Animal Planet |
| 501 |
Ended |
-1.0 |
0 |
1477142177 |
Bulging Brides |
English |
2008-01-31 00:00:00 |
<p><b>Bulging Brides</b> is a television serie... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
CA |
Canada |
Canada/Atlantic |
472 |
Slice |
| 502 |
Running |
6.7 |
0 |
1502923678 |
Never Ever Do This at Home |
English |
2013-05-06 00:00:00 |
<p><b>Never Ever Do This at Home</b> is a come... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
CA |
Canada |
Canada/Atlantic |
298 |
Discovery Channel |
| 503 |
Ended |
-1.0 |
0 |
1465987779 |
Hello Ross |
English |
2013-09-06 00:00:00 |
<p><i><b>"Hello Ross"</b></i> is the new weekl... |
30 |
Talk Show |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
43 |
E! |
| 504 |
Ended |
-1.0 |
0 |
1499803314 |
3 |
English |
2012-07-26 00:00:00 |
<p><b>3</b> is a new relationship series in wh... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
2 |
CBS |
| 505 |
Ended |
-1.0 |
0 |
1495568447 |
Trexx and Flipside |
English |
0 |
<p>Wannabe hip hop stars but their music label... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
GB |
United Kingdom |
Europe/London |
49 |
BBC Three |
| 506 |
Running |
8.5 |
96 |
1503483430 |
The Real Housewives of Orange County |
English |
2006-03-21 00:00:00 |
<p>These ladies show no signs of slowing down ... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
52 |
Bravo |
| 507 |
Ended |
5.3 |
16 |
1479782037 |
Skins |
English |
2011-01-17 00:00:00 |
<p><b>Skins</b> is about the lives and loves o... |
60 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
22 |
MTV |
| 508 |
Running |
-1.0 |
73 |
1503490679 |
Dr. Phil |
English |
2002-09-16 00:00:00 |
<p>The <b>Dr. Phil</b> show provides the most ... |
60 |
Talk Show |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
72 |
Syndication |
| 509 |
Running |
7.5 |
50 |
1497449904 |
My Big Fat American Gypsy Wedding |
English |
2012-04-29 00:00:00 |
<p>Going inside the hidden world of American G... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
80 |
TLC |
| 510 |
Running |
1.0 |
0 |
1479731918 |
Mystery Diners |
English |
2012-05-20 00:00:00 |
<p>When a restaurant owner suspects employees ... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
81 |
Food Network |
| 511 |
Running |
-1.0 |
0 |
1498393231 |
Pig Goat Banana Cricket |
English |
2015-07-18 00:00:00 |
<p><b>Pig Goat Banana Cricket</b> features a s... |
30 |
Animation |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
73 |
nicktoons |
| 512 |
Ended |
-1.0 |
9 |
1460230772 |
Jerseylicious |
English |
2010-03-21 00:00:00 |
<p>Jerseylicious is a reality show which takes... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
184 |
Esquire Network |
| 513 |
Ended |
-1.0 |
38 |
1501384818 |
South Beach Tow |
English |
2011-07-20 00:00:00 |
<p>The <b>South Beach Tow</b> crew returns to ... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
84 |
truTV |
| 514 |
Ended |
-1.0 |
0 |
1466882679 |
Starhyke |
English |
2009-11-30 00:00:00 |
<p>It's the year 3034. Everyone on Earth has b... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
GB |
United Kingdom |
Europe/London |
324 |
Showcase TV |
| 515 |
Ended |
-1.0 |
0 |
1496675604 |
Making the Band |
English |
2000-03-24 00:00:00 |
<p><b>Making the Band</b> was the brainchild o... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
22 |
MTV |
| 516 |
Running |
4.5 |
68 |
1480821374 |
Second Jen |
English |
2016-08-28 00:00:00 |
<p><b>Second Jen</b> is a ground-breaking scri... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
CA |
Canada |
Canada/Atlantic |
151 |
City |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 598 |
Ended |
-1.0 |
0 |
1502593090 |
CeeLo Green's The Good Life |
English |
2014-06-23 00:00:00 |
<p>Follow CeeLo as he tackles not only a packe... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
32 |
TBS |
| 599 |
Ended |
-1.0 |
0 |
1477193480 |
America's Prom Queen |
English |
2008-03-17 00:00:00 |
<p><b>America's Prom Queen</b> is a reality TV... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
26 |
FreeForm |
| 600 |
Ended |
-1.0 |
0 |
1461445299 |
Hollywood Me |
English |
2013-06-19 00:00:00 |
<p>Martyn Lawrence Bullard's normal clients in... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
GB |
United Kingdom |
Europe/London |
45 |
Channel 4 |
| 607 |
Ended |
-1.0 |
52 |
1490313454 |
Utopia |
English |
2014-09-07 00:00:00 |
<p>Get ready to witness the birth of a brave n... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
4 |
FOX |
| 608 |
Running |
-1.0 |
93 |
1499236738 |
Storage Wars: Canada |
English |
2013-08-29 00:00:00 |
<p>On a daily basis, high-stakes buyers descen... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
CA |
Canada |
Canada/Atlantic |
350 |
OLN |
| 609 |
Ended |
-1.0 |
0 |
1502217322 |
Big Brother |
English |
2001-04-23 00:00:00 |
<p><b>Big Brother Australia</b> is based on th... |
None |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
AU |
Australia |
Australia/Sydney |
120 |
Nine Network |
| 610 |
Ended |
-1.0 |
0 |
1497307824 |
The Vineyard |
English |
2013-07-23 00:00:00 |
<p>ABC Family's newest original docu-series, <... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
26 |
FreeForm |
| 611 |
Running |
-1.0 |
0 |
1503655502 |
Na dobre i na złe |
Polish |
1999-11-07 00:00:00 |
|
60 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
PL |
Poland |
Europe/Warsaw |
333 |
TVP2 |
| 612 |
Ended |
-1.0 |
0 |
1477348482 |
Big Top |
English |
2009-12-02 00:00:00 |
<p><b>Big Top</b> was a sit-com that aired on ... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
GB |
United Kingdom |
Europe/London |
12 |
BBC One |
| 613 |
Running |
9.0 |
0 |
1468322551 |
MTV Suspect |
English |
2016-02-23 00:00:00 |
<p>Across America, people are hiding deep secr... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
22 |
MTV |
| 614 |
Ended |
-1.0 |
0 |
1497305713 |
Kimora Life in the Fab Lane |
English |
2007-08-05 00:00:00 |
<p>A glimpse into the life of former model Kim... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
43 |
E! |
| 615 |
Ended |
-1.0 |
0 |
1490293113 |
Celebrities Undercover |
English |
2014-03-18 00:00:00 |
<p>Celebrities are used to transforming into o... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
79 |
Oxygen |
| 616 |
Running |
-1.0 |
0 |
1458216770 |
Recipe for Deception |
English |
2016-01-21 00:00:00 |
<p>Bravo Media cooks up a battle of secrets an... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
52 |
Bravo |
| 617 |
Ended |
-1.0 |
0 |
1481538915 |
16 Kids and Counting |
English |
2013-01-11 00:00:00 |
<p>What's life like when you have enough child... |
60 |
Documentary |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
GB |
United Kingdom |
Europe/London |
45 |
Channel 4 |
| 618 |
Ended |
-1.0 |
0 |
1484475919 |
A Poet's Guide to Britain |
English |
2009-05-04 00:00:00 |
<p>Poet and author Owen Sheers presents a seri... |
30 |
Documentary |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
GB |
United Kingdom |
Europe/London |
51 |
BBC Four |
| 619 |
Running |
-1.0 |
94 |
1502640953 |
The Bold and the Beautiful |
English |
1987-03-23 00:00:00 |
<p>They created a dynasty where passion rules,... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
2 |
CBS |
| 620 |
Running |
-1.0 |
99 |
1502485797 |
Life of Kylie |
English |
2017-08-06 00:00:00 |
<p><b>Life of Kylie</b> will follow Kylie Jenn... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
43 |
E! |
| 621 |
Ended |
6.0 |
0 |
1502487937 |
Jersey Shore |
English |
2009-12-03 00:00:00 |
<p>Grab your hair gel, wax that Cadillac and g... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
43 |
E! |
| 622 |
Ended |
-1.0 |
0 |
1485103110 |
The Hills |
English |
2006-05-31 00:00:00 |
<p>In the final season of <b>The Hills</b> - K... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
22 |
MTV |
| 623 |
Running |
2.7 |
91 |
1500442171 |
Teen Mom |
English |
2009-12-08 00:00:00 |
<p>In 16 and Pregnant, they were moms-to-be. N... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
22 |
MTV |
| 624 |
Ended |
5.7 |
66 |
1489774713 |
Coupling |
English |
2003-09-25 00:00:00 |
<p><b>Coupling</b> is an American remake of th... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
1 |
NBC |
| 625 |
Running |
-1.0 |
0 |
1486846250 |
Access Hollywood Live |
English |
1996-09-09 00:00:00 |
<p><b>Access Hollywood Live</b> is a weekday t... |
60 |
Variety |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
75 |
REELZ |
| 626 |
To Be Determined |
-1.0 |
0 |
1462596807 |
The First Family |
English |
2012-09-17 00:00:00 |
<p><i><b>"The First Family"</b></i> is an Amer... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
5 |
The CW |
| 627 |
Ended |
10.0 |
0 |
1502461972 |
Garbage Pail Kids |
English |
0 |
<p>From deep within the historic TV animation ... |
25 |
Animation |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
2 |
CBS |
| 628 |
Ended |
-1.0 |
50 |
1497743151 |
Khloé & Lamar |
English |
2011-04-10 00:00:00 |
<p>In <b>Khloé & Lamar</b>, cameras will f... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
43 |
E! |
| 629 |
Ended |
-1.0 |
0 |
1482948423 |
The Paul Reiser Show |
English |
2011-04-14 00:00:00 |
<p>Paul Reiser plays a fictional version of hi... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
1 |
NBC |
| 630 |
Ended |
-1.0 |
0 |
1485719969 |
Pretty Wicked Moms |
English |
2013-06-04 00:00:00 |
<p>Six Atlanta moms give a whole new meaning t... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
18 |
Lifetime |
| 631 |
Ended |
-1.0 |
0 |
1502430474 |
The Wright Way |
English |
2013-04-23 00:00:00 |
<p>Gerald Wright runs the Baselricky Council H... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
GB |
United Kingdom |
Europe/London |
12 |
BBC One |
| 632 |
Ended |
-1.0 |
0 |
1474119411 |
High School Musical: Get in the Picture |
English |
2008-07-20 00:00:00 |
<p>A group of teenagers are invited to partici... |
60 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
3 |
ABC |
| 633 |
Ended |
-1.0 |
0 |
1477283569 |
Audrina |
English |
2011-04-17 00:00:00 |
<p>Besides Audrina's blossoming career and tum... |
30 |
Reality |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
US |
United States |
America/New_York |
55 |
VH1 |
141 rows × 103 columns
# What do we have that is mostly complete
print df_shows[~df_shows.isnull().any(axis=1)]['winner'].value_counts()
df_shows_notnull = df_shows[~df_shows.isnull().any(axis=1)]
1 209
0 117
Name: winner, dtype: int64
# In the processing above, NaNs were replaced by other values for some columns. This block creates a new
# dataframe where all rows with these coded values representing missing data have been removed.
df_shows_complete = df_shows_notnull[(df_shows_notnull['rating'] != -1) & \
(df_shows_notnull['gn_unknown'] != 1) & \
(df_shows_notnull['sched_unknown'] != 1) & \
(df_shows_notnull['sched_time_unknown'] != 1) & \
(df_shows_notnull['country_code'] != '') & \
(df_shows_notnull['country_name'] != '') & \
(df_shows_notnull['country_tz'] != '') & \
(df_shows_notnull['network_id'] != '') & \
(df_shows_notnull['network_name'] != '') & \
(df_shows_notnull['premiered'] != 0)]
# Cool, at least not missing any summaries for samples that are otherwise complete
df_shows_complete['summary'].isnull().sum()
df_shows[['summary', 'winner']].groupby(['winner']).count()
|
summary |
| winner |
|
| 0 |
256 |
| 1 |
235 |
Modeling Section
– Note: Cells in this section must be run sequentially to obtain correct results as some variables are reused in the various modeling sections
Vectorize summary text in different ways
# I'll first try a model with just the summary text, that is available for 491 shows, 256 loosers and 235 winners
# Use NLP techniques to create lots of factors
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer
from collections import Counter
# Use different Vectorizers to find ngrams for us
tfidf = TfidfVectorizer(ngram_range=(2,4), max_features=2000, stop_words='english')
cvec = CountVectorizer(ngram_range=(2,4), max_features=2000, stop_words='english')
hvec = HashingVectorizer(ngram_range=(2,4), n_features=2000, stop_words='english')
X_tfidf = tfidf.fit_transform(df_shows['summary']).todense()
X_cvec = cvec.fit_transform(df_shows['summary']).todense()
X_hvec = hvec.fit_transform(df_shows['summary']).todense()
y = df_shows['winner'].values
print '\ntfidf shape:', X_tfidf.shape
print '\ncvec shape:', X_cvec.shape
print '\nhvec shape:', X_hvec.shape
print len(y)
tfidf shape: (491, 2000)
cvec shape: (491, 2000)
hvec shape: (491, 2000)
491
Model on summary text using Count Vectorizer
- results were best when Count Vectorizer scores were modeled with Gaussian Naive Bayes
Features: 2000
Train Set Accuracy: 0.905
CrossVal Accuracy: 0.644 +/- 0.028
Test Set Accuracy: 0.626
**n-grams with higest cumulative sum of tf-idf scores for winners: ** ‘drama series’, ‘david attenborough’, ‘tells story’, ‘young boy’, ‘anthology series’, ‘documentary series’, ‘years later’, ‘main character’, ‘trials tribulations’, ‘crime drama’, ‘serial killer’, ‘tv history’, ‘super hero’, ‘story starts goku’, ‘starts goku’, ‘story starts’, ‘american television’, ‘fictional town’, ‘television drama’, ‘american crime’
**n-grams with higest cumulative sum of tf-idf scores for losers: ** ‘real housewives’, ‘television series’, ‘reality series’, ‘follows lives’, ‘series produced’, ‘pop culture’, ‘reality television’, ‘reality television series’, ‘animated series’, ‘come true’, ‘aired abc’, ‘reality tv’, ‘series debuted’, ‘real housewives orange county’, ‘real housewives orange’, ‘housewives orange’, ‘housewives orange county’, ‘talk hosted’, ‘studio audience’, ‘cash prize’
# Baseline for training set
winner_avg = y.mean()
baseline = max(winner_avg, 1-winner_avg)
print baseline
# Test Train Split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_cvec, y, test_size=0.25)
print X_train.shape, len(y_train)
print X_test.shape, len(y_test)
(368, 2000) 368
(123, 2000) 123
# Standardize -
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
Xs_train = ss.fit_transform(X_train)
Xs_test = ss.transform(X_test)
# Run lots of classifiers on this and see which perform the best
# Import all the modeling libraries
from sklearn import metrics
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
from catboost import CatBoostClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split, cross_val_score, cross_val_predict, \
KFold, StratifiedKFold, GridSearchCV
from sklearn.metrics import accuracy_score, precision_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
# prepare configuration for cross validation test harness
seed = 42
# prepare models
models = []
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('QDA', QuadraticDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('RFST', RandomForestClassifier()))
models.append(('GB', GradientBoostingClassifier()))
models.append(('ADA', AdaBoostClassifier()))
models.append(('SVM', SVC()))
models.append(('GNB', GaussianNB()))
models.append(('MNB', MultinomialNB()))
models.append(('BNB', BernoulliNB()))
# evaluate each model in turn
results = []
names = []
scoring = 'accuracy'
print "\n{}: {:0.3} ".format('Baseline', baseline, cv_results.std())
print "\n{:5.5}: {:10.8} {:20.18} {:20.17} {:20.17}".format\
("Model", "Features", "Train Set Accuracy", "CrossVal Accuracy", "Test Set Accuracy")
for name, model in models:
try:
kfold = KFold(n_splits=3, shuffle=True, random_state=seed)
cv_results = cross_val_score(model, Xs_train, y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
this_model = model
this_model.fit(X_train,y_train)
print "{:5.5} {:} {:0.3f} {:0.3f} +/- {:0.3f} {:0.3f} ".format\
(name, X_train.shape[1], metrics.accuracy_score(y_train, this_model.predict(Xs_train)), \
cv_results.mean(), cv_results.std(), metrics.accuracy_score(y_test, this_model.predict(Xs_test)))
except:
print " {:5.5}: {} ".format(name, 'failed on this input dataset')
# boxplot algorithm comparison
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
ax.axhline(y=baseline, color='grey', linestyle='--')
plt.show()
Baseline: 0.521
Model: Features Train Set Accuracy CrossVal Accuracy Test Set Accuracy
LR 2000 0.938 0.660 +/- 0.037 0.626
LDA 2000 0.938 0.544 +/- 0.054 0.593
QDA 2000 0.549 0.399 +/- 0.034 0.390
KNN 2000 0.758 0.500 +/- 0.010 0.528
CART 2000 0.943 0.576 +/- 0.028 0.585
RFST 2000 0.940 0.636 +/- 0.046 0.626
GB 2000 0.826 0.546 +/- 0.020 0.585
ADA 2000 0.769 0.552 +/- 0.042 0.545
SVM 2000 0.519 0.519 +/- 0.018 0.528
GNB 2000 0.913 0.688 +/- 0.038 0.561
MNB : failed on this input dataset
BNB 2000 0.902 0.625 +/- 0.023 0.602
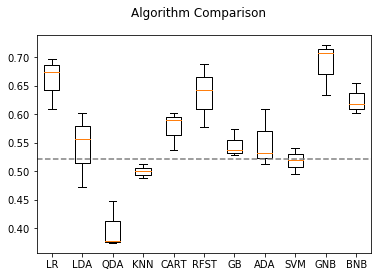
# Which words are most common in the winner summaries ?
from sklearn.feature_extraction.text import CountVectorizer
from collections import Counter
# We can use the TfidfVectorizer to find ngrams for us
vect = CountVectorizer(ngram_range=(2,4), stop_words='english')
# Pulls all of trumps tweet text's into one giant string
summaries = "".join(df_shows[df_shows['winner'] == 1]['summary'])
ngrams_summaries = vect.build_analyzer()(summaries)
Counter(ngrams_summaries).most_common(20)
[(u'new york', 11),
(u'drama series', 8),
(u'york city', 6),
(u'high school', 6),
(u'men women', 5),
(u'tv series', 5),
(u'series based', 5),
(u'video game', 5),
(u'bugs bunny', 5),
(u'new york city', 5),
(u'tells story', 4),
(u'young boy', 4),
(u'comedy series', 4),
(u'main character', 4),
(u'united states', 4),
(u'life new', 4),
(u'series follows', 4),
(u'anthology series', 3),
(u'mr bean', 3),
(u'prisoner cell', 3)]
# Which words are most common in the loser summaries ?
from sklearn.feature_extraction.text import CountVectorizer
from collections import Counter
# We can use the TfidfVectorizer to find ngrams for us
vect = CountVectorizer(ngram_range=(2,4), stop_words='english')
# Pulls all of trumps tweet text's into one giant string
summaries = "".join(df_shows[df_shows['winner'] == 0]['summary'])
ngrams_summaries = vect.build_analyzer()(summaries)
Counter(ngrams_summaries).most_common(20)
[(u'real housewives', 12),
(u'television series', 12),
(u'los angeles', 11),
(u'pop culture', 10),
(u'series follows', 9),
(u'new york', 9),
(u'animated series', 7),
(u'cartoon network', 7),
(u'big brother', 6),
(u'dance moms', 6),
(u'reality series', 6),
(u'best friend', 6),
(u'high school', 5),
(u'late night', 5),
(u'best friends', 5),
(u'nick jr', 5),
(u'reality television series', 5),
(u'plastic surgery', 5),
(u'access hollywood', 5),
(u'comedy series', 5)]
# Sum matrix columns to see what has the most overall importance ?
print "Highest sum Count Vectoror score for n_grams in winner shows"
cvec_results = pd.DataFrame(Xs_train, columns=cvec.get_feature_names())
cvec_results['winners'] = y_train
winner_results = pd.DataFrame(cvec_results[cvec_results['winners'] ==1].sum(), columns=['cvec_sum'])
high = winner_results.drop(['winners']).sort_values('cvec_sum', axis=0, ascending=False).head(20).index
print [str(r) for r in high]
winner_results.drop(['winners']).sort_values('cvec_sum', axis=0, ascending=False).head(20)
Highest sum Count Vectoror score for n_grams in winner shows
['drama series', 'david attenborough', 'main character', 'tells story', 'years later', 'years ago', 'fictional town', 'anthology series', 'documentary series', 'provocative series', 'makes effort', 'standup comedian', 'set world', 'time 13yearold', 'based manga', 'highs lows', 'set fictional', 'sherlock holmes', 'series takes', 'seaside town']
|
cvec_sum |
| drama series |
21.615324 |
| david attenborough |
20.022240 |
| main character |
20.022240 |
| tells story |
20.022240 |
| years later |
17.315999 |
| years ago |
17.315999 |
| fictional town |
17.315999 |
| anthology series |
17.315999 |
| documentary series |
17.315999 |
| provocative series |
14.119126 |
| makes effort |
14.119126 |
| standup comedian |
14.119126 |
| set world |
14.119126 |
| time 13yearold |
14.119126 |
| based manga |
14.119126 |
| highs lows |
14.119126 |
| set fictional |
14.119126 |
| sherlock holmes |
14.119126 |
| series takes |
14.119126 |
| seaside town |
14.119126 |
# Sum matrix columns to see what has the most overall importance ?
print "Highest sum Count Vectoror score for n_grams in loser shows"
cvec_results = pd.DataFrame(Xs_train, columns=cvec.get_feature_names())
cvec_results['winners'] = y_train
winner_results = pd.DataFrame(cvec_results[cvec_results['winners'] ==0].sum(), columns=['cvec_sum'])
high = winner_results.drop(['winners']).sort_values('cvec_sum', axis=0, ascending=False).head(20).index
print [str(r) for r in high]
winner_results.drop(['winners']).sort_values('cvec_sum', axis=0, ascending=False).head(20)
Highest sum Count Vectoror score for n_grams in loser shows
['reality series', 'television series', 'series produced', 'real housewives', 'series debuted', 'family friends', 'follows lives', 'series features', 'animated series', 'los angeles', 'reality television', 'reality television series', 'bros television distribution', 'bros television', 'warner bros television', 'warner bros television distribution', 'television series debuted', 'cash prize', 'new series', 'news channel']
|
cvec_sum |
| reality series |
22.787391 |
| television series |
21.394240 |
| series produced |
20.773274 |
| real housewives |
19.851334 |
| series debuted |
18.554642 |
| family friends |
18.554642 |
| follows lives |
18.554642 |
| series features |
18.554642 |
| animated series |
18.554642 |
| los angeles |
18.313960 |
| reality television |
17.522176 |
| reality television series |
17.522176 |
| bros television distribution |
16.046764 |
| bros television |
16.046764 |
| warner bros television |
16.046764 |
| warner bros television distribution |
16.046764 |
| television series debuted |
16.046764 |
| cash prize |
16.046764 |
| new series |
16.046764 |
| news channel |
16.046764 |
Model on summary text using TF-IDF Vectorizer
- results were best when tf-idf scores were modeled with Gaussian Naive Bayes
Features: 2000
Train Set Accuracy: 0.924
CrossVal Accuracy: 0.609 +/- 0.034
Test Set Accuracy: 0.609 +/- 0.034
**n-grams with higest cumulative sum of tf-idf scores for winners: ** ‘david attenborough’, ‘drama series’, ‘men women’, ‘new york’, ‘documentary series’, ‘new york city’, ‘york city’, ‘quest save’, ‘tv series’, ‘world know’, ‘television drama’, ‘sitcom set’, ‘young boy’, ‘comedy series’, ‘series created’, ‘tells story’, ’21st century’, ‘super hero’, ‘cable news’, ‘best friends’
**n-grams with higest cumulative sum of tf-idf scores for losers: ** ‘real housewives’, ‘series follows’, ‘television series’, ‘best friends’, ‘best friend’, ‘los angeles’, ‘things just’, ‘group teenagers’, ‘series features’, ‘restaurant industry’, ‘children ages’, ‘animated series’, ‘big brother’, ‘cartoon network’, ‘recent divorce’, ‘american women’, ‘high school’, ‘reality series’, ‘follows lives’, ‘lives loves’
# Baseline for training set
winner_avg = y.mean()
baseline = max(winner_avg, 1-winner_avg)
print baseline
# Test Train Split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_tfidf, y, test_size=0.25)
print X_train.shape, len(y_train)
print X_test.shape, len(y_test)
(368, 2000) 368
(123, 2000) 123
# Standardize -
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
Xs_train = ss.fit_transform(X_train)
Xs_test = ss.transform(X_test)
# prepare configuration for cross validation test harness
seed = 42
# prepare models
models = []
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('QDA', QuadraticDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('RFST', RandomForestClassifier()))
models.append(('GB', GradientBoostingClassifier()))
models.append(('ADA', AdaBoostClassifier()))
models.append(('SVM', SVC()))
models.append(('GNB', GaussianNB()))
models.append(('MNB', MultinomialNB()))
models.append(('BNB', BernoulliNB()))
# evaluate each model in turn
results = []
names = []
scoring = 'accuracy'
print "\n{}: {:0.3} ".format('Baseline', baseline, cv_results.std())
print "\n{:5.5}: {:10.8} {:20.18} {:20.17} {:20.17}".format\
("Model", "Features", "Train Set Accuracy", "CrossVal Accuracy", "Test Set Accuracy")
for name, model in models:
try:
kfold = KFold(n_splits=3, shuffle=True, random_state=seed)
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
this_model = model
this_model.fit(X_train,y_train)
print "{:5.5} {:} {:0.3f} {:0.3f} +/- {:0.3f} {:0.3f} ".format\
(name, X_train.shape[1], metrics.accuracy_score(y_train, this_model.predict(X_train)), \
cv_results.mean(), cv_results.std(), metrics.accuracy_score(y_test, this_model.predict(X_test)))
except:
print " {:5.5}: {} ".format(name, 'failed on this input dataset')
# boxplot algorithm comparison
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
ax.axhline(y=baseline, color='grey', linestyle='--')
plt.show()
Baseline: 0.521
Model: Features Train Set Accuracy CrossVal Accuracy Test Set Accuracy
LR 2000 0.957 0.620 +/- 0.020 0.634
LDA 2000 0.959 0.658 +/- 0.035 0.610
QDA 2000 0.671 0.437 +/- 0.013 0.431
KNN 2000 0.647 0.519 +/- 0.031 0.488
CART 2000 0.959 0.554 +/- 0.026 0.496
RFST 2000 0.957 0.581 +/- 0.020 0.561
GB 2000 0.872 0.598 +/- 0.034 0.545
ADA 2000 0.772 0.541 +/- 0.047 0.504
SVM 2000 0.505 0.492 +/- 0.009 0.569
GNB 2000 0.943 0.668 +/- 0.028 0.634
MNB 2000 0.927 0.658 +/- 0.029 0.642
BNB 2000 0.932 0.641 +/- 0.048 0.593
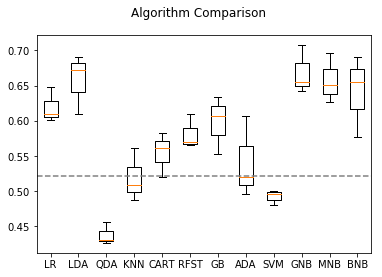
# Which words are most common in the winner summaries ?
from sklearn.feature_extraction.text import TfidfVectorizer
from collections import Counter
# We can use the TfidfVectorizer to find ngrams for us
vect = TfidfVectorizer(ngram_range=(2,4), stop_words='english')
# Pulls all of trumps tweet text's into one giant string
summaries = "".join(df_shows[df_shows['winner'] == 1]['summary'])
ngrams_summaries = vect.build_analyzer()(summaries)
Counter(ngrams_summaries).most_common(20)
[(u'new york', 11),
(u'drama series', 8),
(u'york city', 6),
(u'high school', 6),
(u'men women', 5),
(u'tv series', 5),
(u'series based', 5),
(u'video game', 5),
(u'bugs bunny', 5),
(u'new york city', 5),
(u'tells story', 4),
(u'young boy', 4),
(u'comedy series', 4),
(u'main character', 4),
(u'united states', 4),
(u'life new', 4),
(u'series follows', 4),
(u'anthology series', 3),
(u'mr bean', 3),
(u'prisoner cell', 3)]
# Which words are most common in the loser summaries ?
from sklearn.feature_extraction.text import TfidfVectorizer
from collections import Counter
# We can use the TfidfVectorizer to find ngrams for us
vect = TfidfVectorizer(ngram_range=(2,4), stop_words='english')
# Pulls all of trumps tweet text's into one giant string
summaries = "".join(df_shows[df_shows['winner'] == 0]['summary'])
ngrams_summaries = vect.build_analyzer()(summaries)
Counter(ngrams_summaries).most_common(20)
[(u'real housewives', 12),
(u'television series', 12),
(u'los angeles', 11),
(u'pop culture', 10),
(u'series follows', 9),
(u'new york', 9),
(u'animated series', 7),
(u'cartoon network', 7),
(u'big brother', 6),
(u'dance moms', 6),
(u'reality series', 6),
(u'best friend', 6),
(u'high school', 5),
(u'late night', 5),
(u'best friends', 5),
(u'nick jr', 5),
(u'reality television series', 5),
(u'plastic surgery', 5),
(u'access hollywood', 5),
(u'comedy series', 5)]
# Sum matrix columns to see what has the most overall importance ?
print "Highest cumulative tfidf score for n_grams in winner shows"
tfidf_results = pd.DataFrame(X_train, columns= tfidf.get_feature_names())
tfidf_results['winners'] = y_train
winner_results = pd.DataFrame(tfidf_results[tfidf_results['winners'] ==1].sum(), columns=['tfidf_sum'])
high = winner_results.drop(['winners']).sort_values('tfidf_sum', axis=0, ascending=False).head(20).index
print [str(r) for r in high]
winner_results.drop(['winners']).sort_values('tfidf_sum', axis=0, ascending=False).head(20)
Highest cumulative tfidf score for n_grams in winner shows
['new york', 'men women', 'documentary series', 'york city', 'new york city', 'high school', 'drama series', 'tells story', 'years ago', 'david attenborough', 'series created', 'years later', 'young man', 'comedy series', 'main character', '21st century', 'tv series', 'andrew davies', 'cable news', 'series based']
|
tfidf_sum |
| new york |
2.835972 |
| men women |
2.484786 |
| documentary series |
2.171334 |
| york city |
1.897754 |
| new york city |
1.897754 |
| high school |
1.743989 |
| drama series |
1.716267 |
| tells story |
1.685216 |
| years ago |
1.634339 |
| david attenborough |
1.522240 |
| series created |
1.484294 |
| years later |
1.484223 |
| young man |
1.474759 |
| comedy series |
1.401982 |
| main character |
1.366767 |
| 21st century |
1.358933 |
| tv series |
1.307707 |
| andrew davies |
1.304276 |
| cable news |
1.261358 |
| series based |
1.258897 |
# Sum matrix columns to see what has the most overall importance ?
print "Highest cumulative tfidf score for n_grams in loser shows"
tfidf_results = pd.DataFrame(X_train, columns= tfidf.get_feature_names())
tfidf_results['winners'] = y_train
winner_results = pd.DataFrame(tfidf_results[tfidf_results['winners'] == 0].sum(), columns=['tfidf_sum'])
low = winner_results.drop(['winners']).sort_values('tfidf_sum', axis=0, ascending=False).head(20).index
print [str(r) for r in low]
winner_results.drop(['winners']).sort_values('tfidf_sum', axis=0, ascending=False).head(20)
Highest cumulative tfidf score for n_grams in loser shows
['reality series', 'television series', 'los angeles', 'real housewives', 'things just', 'best friend', 'group teenagers', 'series follows', 'restaurant industry', 'new york', 'high school', 'children ages', 'big brother', 'recent divorce', 'series features', 'cartoon network', 'football team', 'plastic surgery', 'bizarre adventures', 'nick jr']
|
tfidf_sum |
| reality series |
3.535573 |
| television series |
2.715189 |
| los angeles |
2.582930 |
| real housewives |
2.160853 |
| things just |
2.000000 |
| best friend |
1.958176 |
| group teenagers |
1.791283 |
| series follows |
1.772954 |
| restaurant industry |
1.707107 |
| new york |
1.662150 |
| high school |
1.657534 |
| children ages |
1.648007 |
| big brother |
1.591352 |
| recent divorce |
1.473112 |
| series features |
1.443284 |
| cartoon network |
1.441719 |
| football team |
1.414214 |
| plastic surgery |
1.382887 |
| bizarre adventures |
1.368894 |
| nick jr |
1.366875 |
Model using data other than the TV show summary text
# Get list of columns for the useful non-summary data. Dropping the "unknown" columns will solve
# the colinearity issue with dummied columns, as these will be the dropped dummies.
# Dropping premiered as it is a datatime and standardize can't handle it. Also dropping
# weight as it is not understood, and rating and winner as they are the targets
cols = [x for x in df_shows.columns if x not in ['rating', 'weight', 'updated', 'premiered', 'summary', 'id', \
'gn_unknown', 'sched_unknown', 'sched_time_unknown', \
'country_name', 'country_tz', 'network_name', 'name', 'winner']]
cols
[u'status',
u'language',
u'runtime',
u'type',
u'network',
u'gn_action',
u'gn_adult',
u'gn_adventure',
u'gn_anime',
u'gn_children',
u'gn_comedy',
u'gn_crime',
u'gn_drama',
u'gn_espionage',
u'gn_family',
u'gn_fantasy',
u'gn_food',
u'gn_history',
u'gn_horror',
u'gn_legal',
u'gn_medical',
u'gn_music',
u'gn_mystery',
u'gn_nature',
u'gn_romance',
u'gn_science-fiction',
u'gn_sports',
u'gn_supernatural',
u'gn_thriller',
u'gn_travel',
u'gn_war',
u'gn_western',
u'sched_friday',
u'sched_monday',
u'sched_saturday',
u'sched_sunday',
u'sched_thursday',
u'sched_tuesday',
u'sched_wednesday',
u'sched_time_00:00',
u'sched_time_00:30',
u'sched_time_00:50',
u'sched_time_00:55',
u'sched_time_01:00',
u'sched_time_01:05',
u'sched_time_01:30',
u'sched_time_01:35',
u'sched_time_02:00',
u'sched_time_02:05',
u'sched_time_08:00',
u'sched_time_10:00',
u'sched_time_11:00',
u'sched_time_12:00',
u'sched_time_13:00',
u'sched_time_13:30',
u'sched_time_14:00',
u'sched_time_14:30',
u'sched_time_15:00',
u'sched_time_15:15',
u'sched_time_16:00',
u'sched_time_16:30',
u'sched_time_17:00',
u'sched_time_17:15',
u'sched_time_17:30',
u'sched_time_18:00',
u'sched_time_18:30',
u'sched_time_19:00',
u'sched_time_19:30',
u'sched_time_19:45',
u'sched_time_20:00',
u'sched_time_20:15',
u'sched_time_20:30',
u'sched_time_20:40',
u'sched_time_20:45',
u'sched_time_20:55',
u'sched_time_21:00',
u'sched_time_21:10',
u'sched_time_21:15',
u'sched_time_21:30',
u'sched_time_21:45',
u'sched_time_22:00',
u'sched_time_22:10',
u'sched_time_22:30',
u'sched_time_22:35',
u'sched_time_23:00',
u'sched_time_23:02',
u'sched_time_23:15',
u'sched_time_23:30',
'country_code',
'network_id']
# Dummy country code, network id, status, language, and type
df_showsd = pd.get_dummies(df_shows, columns=['network_id'], prefix='NW', prefix_sep='_')
df_showsd = df_showsd.drop('NW_', 1)
df_showsd = df_showsd.drop('network', 1)
df_showsd = pd.get_dummies(df_showsd, columns=['country_code'], prefix='C', prefix_sep='_', drop_first=True)
df_showsd = pd.get_dummies(df_showsd, columns=['status'], prefix='ST', prefix_sep='_', drop_first=True)
df_showsd = pd.get_dummies(df_showsd, columns=['language'], prefix='L', prefix_sep='_', drop_first=True)
df_showsd = pd.get_dummies(df_showsd, columns=['type'], prefix='T', prefix_sep='_', drop_first=True)
# Handle any NaN values that remain
shows_clean = df_showsd.dropna()
# We have 326 total samples left, about 1/3 loser and 2/3 winner
# Seems reasonable to proceed with a classification model
print "Number winner samples:", shows_clean['winner'].sum()
print "Number loser samples:", len(shows_clean[shows_clean['winner'] == 0])
Number winner samples: 230
Number loser samples: 121
cols = [x for x in shows_clean.columns if x not in ['rating', 'weight', 'updated', 'premiered', 'summary', 'id', \
'gn_unknown', 'sched_unknown', 'sched_time_unknown', \
'country_name', 'country_tz', 'network_name', 'name', 'winner']]
cols
[u'runtime',
u'gn_action',
u'gn_adult',
u'gn_adventure',
u'gn_anime',
u'gn_children',
u'gn_comedy',
u'gn_crime',
u'gn_drama',
u'gn_espionage',
u'gn_family',
u'gn_fantasy',
u'gn_food',
u'gn_history',
u'gn_horror',
u'gn_legal',
u'gn_medical',
u'gn_music',
u'gn_mystery',
u'gn_nature',
u'gn_romance',
u'gn_science-fiction',
u'gn_sports',
u'gn_supernatural',
u'gn_thriller',
u'gn_travel',
u'gn_war',
u'gn_western',
u'sched_friday',
u'sched_monday',
u'sched_saturday',
u'sched_sunday',
u'sched_thursday',
u'sched_tuesday',
u'sched_wednesday',
u'sched_time_00:00',
u'sched_time_00:30',
u'sched_time_00:50',
u'sched_time_00:55',
u'sched_time_01:00',
u'sched_time_01:05',
u'sched_time_01:30',
u'sched_time_01:35',
u'sched_time_02:00',
u'sched_time_02:05',
u'sched_time_08:00',
u'sched_time_10:00',
u'sched_time_11:00',
u'sched_time_12:00',
u'sched_time_13:00',
u'sched_time_13:30',
u'sched_time_14:00',
u'sched_time_14:30',
u'sched_time_15:00',
u'sched_time_15:15',
u'sched_time_16:00',
u'sched_time_16:30',
u'sched_time_17:00',
u'sched_time_17:15',
u'sched_time_17:30',
u'sched_time_18:00',
u'sched_time_18:30',
u'sched_time_19:00',
u'sched_time_19:30',
u'sched_time_19:45',
u'sched_time_20:00',
u'sched_time_20:15',
u'sched_time_20:30',
u'sched_time_20:40',
u'sched_time_20:45',
u'sched_time_20:55',
u'sched_time_21:00',
u'sched_time_21:10',
u'sched_time_21:15',
u'sched_time_21:30',
u'sched_time_21:45',
u'sched_time_22:00',
u'sched_time_22:10',
u'sched_time_22:30',
u'sched_time_22:35',
u'sched_time_23:00',
u'sched_time_23:02',
u'sched_time_23:15',
u'sched_time_23:30',
'NW_1',
'NW_2',
'NW_3',
'NW_4',
'NW_5',
'NW_6',
'NW_8',
'NW_9',
'NW_10',
'NW_11',
'NW_12',
'NW_13',
'NW_14',
'NW_16',
'NW_17',
'NW_18',
'NW_19',
'NW_20',
'NW_22',
'NW_23',
'NW_24',
'NW_25',
'NW_26',
'NW_27',
'NW_29',
'NW_30',
'NW_32',
'NW_34',
'NW_35',
'NW_36',
'NW_37',
'NW_41',
'NW_42',
'NW_43',
'NW_44',
'NW_45',
'NW_47',
'NW_48',
'NW_49',
'NW_51',
'NW_52',
'NW_54',
'NW_55',
'NW_56',
'NW_59',
'NW_63',
'NW_66',
'NW_70',
'NW_71',
'NW_72',
'NW_73',
'NW_75',
'NW_76',
'NW_77',
'NW_78',
'NW_79',
'NW_80',
'NW_81',
'NW_84',
'NW_85',
'NW_88',
'NW_91',
'NW_92',
'NW_107',
'NW_109',
'NW_114',
'NW_115',
'NW_118',
'NW_120',
'NW_122',
'NW_125',
'NW_131',
'NW_132',
'NW_137',
'NW_144',
'NW_149',
'NW_151',
'NW_155',
'NW_157',
'NW_158',
'NW_159',
'NW_163',
'NW_173',
'NW_177',
'NW_184',
'NW_185',
'NW_206',
'NW_224',
'NW_231',
'NW_239',
'NW_248',
'NW_251',
'NW_270',
'NW_286',
'NW_298',
'NW_309',
'NW_324',
'NW_333',
'NW_336',
'NW_349',
'NW_350',
'NW_360',
'NW_376',
'NW_409',
'NW_472',
'NW_551',
'NW_553',
'NW_639',
'NW_652',
'NW_714',
'NW_809',
'NW_813',
'NW_821',
'NW_870',
'NW_976',
'NW_1027',
'NW_1050',
'NW_1485',
u'C_AU',
u'C_CA',
u'C_DE',
u'C_DK',
u'C_FR',
u'C_GB',
u'C_IT',
u'C_JP',
u'C_KR',
u'C_NO',
u'C_NZ',
u'C_PL',
u'C_RU',
u'C_SE',
u'C_TR',
u'C_US',
u'ST_Running',
u'ST_To Be Determined',
u'L_English',
u'L_French',
u'L_German',
u'L_Hindi',
u'L_Italian',
u'L_Japanese',
u'L_Korean',
u'L_Norwegian',
u'L_Polish',
u'L_Russian',
u'L_Swedish',
u'L_Turkish',
u'T_Documentary',
u'T_Game Show',
u'T_News',
u'T_Panel Show',
u'T_Reality',
u'T_Scripted',
u'T_Talk Show',
u'T_Variety']
# Generate X matrix and y target
X = shows_clean[cols]
y = shows_clean['winner'].values
# Baseline
winner_avg = y.mean()
baseline = max(winner_avg, 1-winner_avg)
print baseline
# Test Train Split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
print X_train.shape, len(y_train)
print X_test.shape, len(y_test)
(263, 240) 263
(88, 240) 88
# Standardize -
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
Xs_train = ss.fit_transform(X_train)
Xs_test = ss.transform(X_test)# Test Train Split
# Gridsearch for best C and penalty
gs_params = {
'penalty':['l1', 'l2'],
'solver':['liblinear'],
'C':np.logspace(-5,5,100)
}
from sklearn.model_selection import GridSearchCV
lr_gridsearch = GridSearchCV(LogisticRegression(), gs_params, cv=3, verbose=1, n_jobs=-1)
lr_gridsearch.fit(Xs_train, y_train)
Fitting 3 folds for each of 200 candidates, totalling 600 fits
[Parallel(n_jobs=-1)]: Done 196 tasks | elapsed: 0.8s
[Parallel(n_jobs=-1)]: Done 600 out of 600 | elapsed: 1.4s finished
GridSearchCV(cv=3, error_score='raise',
estimator=LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False),
fit_params={}, iid=True, n_jobs=-1,
param_grid={'penalty': ['l1', 'l2'], 'C': array([ 1.00000e-05, 1.26186e-05, ..., 7.92483e+04, 1.00000e+05]), 'solver': ['liblinear']},
pre_dispatch='2*n_jobs', refit=True, return_train_score=True,
scoring=None, verbose=1)
# best score on the training data:
lr_gridsearch.best_score_
# best parameters on the training data:
lr_gridsearch.best_params_
{'C': 0.068926121043496949, 'penalty': 'l2', 'solver': 'liblinear'}
# assign the best estimator to a variable:
best_lr = lr_gridsearch.best_estimator_
# Score it on the testing data:
best_lr.score(Xs_test, y_test)
# Much better than baseline, and we can find the most important factors and run all the classifiers using
# those factors.
coef_df = pd.DataFrame({
'features': X.columns,
'log odds': best_lr.coef_[0],
'percentage change in odds': np.round(np.exp(best_lr.coef_[0])*100-100,2)
})
coef_df.sort_values(by='percentage change in odds', ascending=0)
|
features |
log odds |
percentage change in odds |
| 6 |
gn_comedy |
0.500129 |
64.89 |
| 237 |
T_Scripted |
0.477513 |
61.21 |
| 232 |
T_Documentary |
0.268693 |
30.83 |
| 8 |
gn_drama |
0.254062 |
28.93 |
| 3 |
gn_adventure |
0.246904 |
28.01 |
| 90 |
NW_8 |
0.242839 |
27.49 |
| 94 |
NW_12 |
0.207017 |
23.00 |
| 114 |
NW_37 |
0.201048 |
22.27 |
| 7 |
gn_crime |
0.192888 |
21.27 |
| 83 |
sched_time_23:30 |
0.178175 |
19.50 |
| 21 |
gn_science-fiction |
0.177248 |
19.39 |
| 23 |
gn_supernatural |
0.177209 |
19.39 |
| 18 |
gn_mystery |
0.167534 |
18.24 |
| 95 |
NW_13 |
0.139862 |
15.01 |
| 218 |
ST_Running |
0.139006 |
14.91 |
| 0 |
runtime |
0.138903 |
14.90 |
| 11 |
gn_fantasy |
0.137532 |
14.74 |
| 64 |
sched_time_19:45 |
0.137084 |
14.69 |
| 176 |
NW_270 |
0.126593 |
13.50 |
| 87 |
NW_4 |
0.122341 |
13.01 |
| 143 |
NW_85 |
0.115952 |
12.29 |
| 13 |
gn_history |
0.111519 |
11.80 |
| 24 |
gn_thriller |
0.102413 |
10.78 |
| 30 |
sched_saturday |
0.102229 |
10.76 |
| 207 |
C_GB |
0.101888 |
10.73 |
| 1 |
gn_action |
0.090291 |
9.45 |
| 14 |
gn_horror |
0.088511 |
9.25 |
| 62 |
sched_time_19:00 |
0.086923 |
9.08 |
| 98 |
NW_17 |
0.085510 |
8.93 |
| 225 |
L_Japanese |
0.085179 |
8.89 |
| ... |
... |
... |
... |
| 53 |
sched_time_15:00 |
-0.106270 |
-10.08 |
| 153 |
NW_122 |
-0.113304 |
-10.71 |
| 132 |
NW_71 |
-0.113592 |
-10.74 |
| 201 |
NW_1485 |
-0.115251 |
-10.89 |
| 186 |
NW_376 |
-0.115363 |
-10.90 |
| 169 |
NW_185 |
-0.116553 |
-11.00 |
| 106 |
NW_26 |
-0.117644 |
-11.10 |
| 220 |
L_English |
-0.119882 |
-11.30 |
| 105 |
NW_25 |
-0.126560 |
-11.89 |
| 55 |
sched_time_16:00 |
-0.128590 |
-12.07 |
| 29 |
sched_monday |
-0.134095 |
-12.55 |
| 192 |
NW_652 |
-0.143685 |
-13.38 |
| 217 |
C_US |
-0.154332 |
-14.30 |
| 117 |
NW_43 |
-0.155093 |
-14.37 |
| 110 |
NW_32 |
-0.157596 |
-14.58 |
| 158 |
NW_144 |
-0.158937 |
-14.69 |
| 49 |
sched_time_13:00 |
-0.159660 |
-14.76 |
| 140 |
NW_80 |
-0.160574 |
-14.83 |
| 33 |
sched_tuesday |
-0.174971 |
-16.05 |
| 203 |
C_CA |
-0.179060 |
-16.39 |
| 93 |
NW_11 |
-0.179608 |
-16.44 |
| 17 |
gn_music |
-0.189299 |
-17.25 |
| 179 |
NW_309 |
-0.216452 |
-19.46 |
| 124 |
NW_52 |
-0.224190 |
-20.08 |
| 238 |
T_Talk Show |
-0.233104 |
-20.79 |
| 233 |
T_Game Show |
-0.244726 |
-21.71 |
| 78 |
sched_time_22:30 |
-0.251273 |
-22.22 |
| 102 |
NW_22 |
-0.268289 |
-23.53 |
| 67 |
sched_time_20:30 |
-0.300379 |
-25.95 |
| 236 |
T_Reality |
-0.557917 |
-42.76 |
240 rows × 3 columns
# Create a subset of "coef_df" DataFrame with most important coefficients
imp_coefs = pd.concat([coef_df.sort_values(by='percentage change in odds', ascending=0).head(10),
coef_df.sort_values(by='percentage change in odds', ascending=0).tail(10)])
imp_coefs.set_index('features', inplace=True)
|
log odds |
percentage change in odds |
| features |
|
|
| gn_comedy |
0.500129 |
64.89 |
| T_Scripted |
0.477513 |
61.21 |
| T_Documentary |
0.268693 |
30.83 |
| gn_drama |
0.254062 |
28.93 |
| gn_adventure |
0.246904 |
28.01 |
| NW_8 |
0.242839 |
27.49 |
| NW_12 |
0.207017 |
23.00 |
| NW_37 |
0.201048 |
22.27 |
| gn_crime |
0.192888 |
21.27 |
| sched_time_23:30 |
0.178175 |
19.50 |
| NW_11 |
-0.179608 |
-16.44 |
| gn_music |
-0.189299 |
-17.25 |
| NW_309 |
-0.216452 |
-19.46 |
| NW_52 |
-0.224190 |
-20.08 |
| T_Talk Show |
-0.233104 |
-20.79 |
| T_Game Show |
-0.244726 |
-21.71 |
| sched_time_22:30 |
-0.251273 |
-22.22 |
| NW_22 |
-0.268289 |
-23.53 |
| sched_time_20:30 |
-0.300379 |
-25.95 |
| T_Reality |
-0.557917 |
-42.76 |
# Plot important coefficients
imp_coefs['percentage change in odds'].plot(kind = "barh")
plt.title("Percentage change in odds with Ridge regularization")
plt.show()
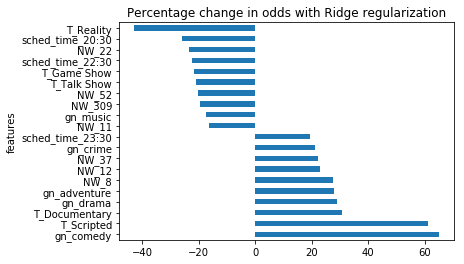
df_shows[df_shows['network_id'] == 309]
|
status |
rating |
weight |
updated |
name |
language |
premiered |
summary |
runtime |
type |
... |
sched_time_23:00 |
sched_time_23:02 |
sched_time_23:15 |
sched_time_23:30 |
sched_time_unknown |
country_code |
country_name |
country_tz |
network_id |
network_name |
| 279 |
Running |
8.7 |
40 |
2017-08-22 19:26:37 |
I Live with Models |
English |
2015-02-23 00:00:00 |
tommy heads to new york city with scarlet as t... |
30 |
Scripted |
... |
0.0 |
0.0 |
0.0 |
0.0 |
0.0 |
GB |
United Kingdom |
Europe/London |
309 |
Comedy Central |
| 535 |
To Be Determined |
6.5 |
0 |
2016-01-13 15:12:17 |
Brotherhood |
English |
2015-06-02 00:00:00 |
twentysomethings dan and toby are in over thei... |
30 |
Scripted |
... |
NaN |
NaN |
NaN |
NaN |
NaN |
GB |
United Kingdom |
Europe/London |
309 |
Comedy Central |
2 rows × 104 columns
# Get list of features and re-run model with just the 20 most important features
imp_features = imp_coefs.index
# Set up X and y
X = shows_clean[imp_features]
y = shows_clean['winner'].values
# Baseline
winner_avg = y.mean()
baseline = max(winner_avg, 1-winner_avg)
print baseline
# Test Train Split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
print X_train.shape, len(y_train)
print X_test.shape, len(y_test)
(263, 20) 263
(88, 20) 88
# Standardize -
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
Xs_train = ss.fit_transform(X_train)
Xs_test = ss.transform(X_test)# Test Train Split
# prepare configuration for cross validation test harness
seed = 42
# prepare models
models = []
models.append(('LR', LogisticRegression()))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('QDA', QuadraticDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('RFST', RandomForestClassifier()))
models.append(('GB', GradientBoostingClassifier()))
models.append(('ADA', AdaBoostClassifier()))
models.append(('SVM', SVC()))
models.append(('GNB', GaussianNB()))
models.append(('MNB', MultinomialNB()))
models.append(('BNB', BernoulliNB()))
# evaluate each model in turn
results = []
names = []
scoring = 'accuracy'
print "\n{}: {:0.3} ".format('Baseline', baseline, cv_results.std())
print "\n{:5.5}: {:10.8} {:20.18} {:20.17} {:20.17}".format\
("Model", "Features", "Train Set Accuracy", "CrossVal Accuracy", "Test Set Accuracy")
for name, model in models:
try:
kfold = KFold(n_splits=3, shuffle=True, random_state=seed)
cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
this_model = model
this_model.fit(X_train,y_train)
print "{:5.5} {:} {:0.3f} {:0.3f} +/- {:0.3f} {:0.3f} ".format\
(name, X_train.shape[1], metrics.accuracy_score(y_train, this_model.predict(X_train)), \
cv_results.mean(), cv_results.std(), metrics.accuracy_score(y_test, this_model.predict(X_test)))
except:
print " {:5.5}: {} ".format(name, 'failed on this input dataset')
# boxplot algorithm comparison
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
ax.axhline(y=baseline, color='grey', linestyle='--')
plt.show()
Baseline: 0.655
Model: Features Train Set Accuracy CrossVal Accuracy Test Set Accuracy
LR 20 0.905 0.874 +/- 0.010 0.909
LDA 20 0.901 0.890 +/- 0.020 0.875
QDA 20 0.669 0.448 +/- 0.082 0.682
KNN 20 0.909 0.905 +/- 0.005 0.886
CART 20 0.943 0.894 +/- 0.019 0.898
RFST 20 0.939 0.909 +/- 0.000 0.886
GB 20 0.943 0.905 +/- 0.020 0.898
ADA 20 0.916 0.897 +/- 0.032 0.920
SVM 20 0.863 0.848 +/- 0.014 0.818
GNB 20 0.616 0.673 +/- 0.057 0.614
MNB 20 0.886 0.886 +/- 0.010 0.898
BNB 20 0.905 0.901 +/- 0.010 0.920